- 1 Pakete laden
- 2 Daten laden
- 3 Forschungsfrage
- 4 Ihre salvatorische Klausel
- 5 Überblick über die Kennzahlen
- 6 Fehlende Werte
- 7 Verteilung der Output-Variablen
- 8 Verteilung der Input-Variablen
- 9 Explorative Analyse
- 10 Budget logarithmieren
- 11 Datensatz umbauen (pivotieren): Moderierender Effekt von Genre
- 12 Korrelation zwischen den Gruppen
- 13 Einfluss von Genre
- 14 Datensatz vereinfachen
- 15 Datensatz aufteilen (Train- und Test)
- 16 Modell 0 (“Nullmodell”)
- 17 Modell 1:
budget_log10 - 18 Unendliche Werte entfernen
- 19 Model 1 Ergebnisse
- 20 Anzahl der Stimmen (
votes) - 21 Modell 2: Anzahl der Stimmen, linear
- 22 Modell 3: Anzahl der Stimmen als Polynomialmodell, quadratisch
- 23 Modell 4: Anzahl der Stimmen als Polynomialmodell, 3. Grades
- 24 Korrelationsmatrix (visualisieren)
- 25 Modell 5: Multiple Regression
- 26 3D-Visualisierung
- 27 Modell 6: Interaktionsmodell
- 28 Rohe Kraft: Schrittweise Regression
- 29 Modellselektion (Modellwahl) – anova
- 30 Modellselektion (Modellwahl) – Prädiktion
- 31 Hm
- 32 Vielleicht so: Vergleich der Modellgüten
- 33 Prüfung der Voraussetzungen
- 34 Bestes Modell
- 35 Vorhersagen
- 36 Einreichen
1 Pakete laden
Mit dem Paket tidyverse laden wir die gängigen “Datenjudo-Befehle”. Außerdem die Befehle zur Datenvisualisierung (d.h. das Paket ggplot2 wird geladen).
library(tidyverse)
library(broom) # Überführt in Dataframes
library(skimr) # Gibt Überblick über deskriptive Statistiken
library(ggstatsplot) # schickeres Streudiagramm
library(rsample) # for data splitting
library(cowplot) # Um mehrere Diagramme zusammenzufügen
library(corrr) # Korrelationsmatrizen
library(yardstick) # Modellgüte berechnen
library(ggfortify) # Autoplot für Modellannahmen
library(modelr) # Komfort für RegressionsanalysenDenken Sie daran, dass Pakete (einmalig) installiert sein müssen, bevor Sie sie laden können (mittels library()).
2 Daten laden
Die Daten dieser Fallstudie “wohnen” in diesem Paket:
library(ggplot2movies)Hier finden Sie einige Erklärung zu dem Datensatz.
Um die Daten (aus einem geladenen Paket) zu laden, verwenden wir den Befehl data():
data("movies")Alternativ könnten Sie die Daten mit read.csv() einlesen, z.B. von einem Server oder aber von Ihrem Computer.
movies <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2movies/movies.csv")(Tipp: Diese Webseite speichert viele Datensätze.)
Werfen wir einen ersten Blick in die Daten, um zu sehen, dass sie korrekt in R importiert wurden:
glimpse(movies)
#> Rows: 58,788
#> Columns: 25
#> $ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
#> $ title <chr> "$", "$1000 a Touchdown", "$21 a Day Once a Month", "$40,0…
#> $ year <int> 1971, 1939, 1941, 1996, 1975, 2000, 2002, 2002, 1987, 1917…
#> $ length <int> 121, 71, 7, 70, 71, 91, 93, 25, 97, 61, 99, 96, 10, 10, 10…
#> $ budget <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ rating <dbl> 6.4, 6.0, 8.2, 8.2, 3.4, 4.3, 5.3, 6.7, 6.6, 6.0, 5.4, 5.9…
#> $ votes <int> 348, 20, 5, 6, 17, 45, 200, 24, 18, 51, 23, 53, 44, 11, 12…
#> $ r1 <dbl> 4.5, 0.0, 0.0, 14.5, 24.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4…
#> $ r2 <dbl> 4.5, 14.5, 0.0, 0.0, 4.5, 4.5, 0.0, 4.5, 4.5, 0.0, 0.0, 0.…
#> $ r3 <dbl> 4.5, 4.5, 0.0, 0.0, 0.0, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5…
#> $ r4 <dbl> 4.5, 24.5, 0.0, 0.0, 14.5, 14.5, 4.5, 4.5, 0.0, 4.5, 14.5,…
#> $ r5 <dbl> 14.5, 14.5, 0.0, 0.0, 14.5, 14.5, 24.5, 4.5, 0.0, 4.5, 24.…
#> $ r6 <dbl> 24.5, 14.5, 24.5, 0.0, 4.5, 14.5, 24.5, 14.5, 0.0, 44.5, 4…
#> $ r7 <dbl> 24.5, 14.5, 0.0, 0.0, 0.0, 4.5, 14.5, 14.5, 34.5, 14.5, 24…
#> $ r8 <dbl> 14.5, 4.5, 44.5, 0.0, 0.0, 4.5, 4.5, 14.5, 14.5, 4.5, 4.5,…
#> $ r9 <dbl> 4.5, 4.5, 24.5, 34.5, 0.0, 14.5, 4.5, 4.5, 4.5, 4.5, 14.5,…
#> $ r10 <dbl> 4.5, 14.5, 24.5, 45.5, 24.5, 14.5, 14.5, 14.5, 24.5, 4.5, …
#> $ mpaa <chr> "", "", "", "", "", "", "R", "", "", "", "", "", "", "", "…
#> $ Action <int> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0…
#> $ Animation <int> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1…
#> $ Comedy <int> 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1…
#> $ Drama <int> 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0…
#> $ Documentary <int> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0…
#> $ Romance <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
#> $ Short <int> 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1…Sieht alles gut aus.
Die Namen der Variablen sind (wie so oft) nicht selbsterklärend. Werfen wir einen Blick in die Hilfe.
help(movies)3 Forschungsfrage
Wie gut kann man den Erfolg eines Films vorhersagen? Als Erfolg definieren wir die Höhe der Beurteilung (
rating).Welche Faktoren sind nützlich für die Güte dieser Vorhersage?
4 Ihre salvatorische Klausel
Es könnte sein, dass Sie in dieser Fallstudie auf Ideen (oder R-Syntax) treffen, die Sie nicht kennen. Lassen Sie sich nicht davon ins Boxhorn jagen. Verarbeiten Sie einfach die Teile, die Sie verstehen. Diese Fallstudie soll kein Lehrtext zu den theoretischen Hintergründen sein; daher habe ich auf Erklärungen und Theorie weitgehend verzichtet. Hier geht es um das praktische Tun. Ich wünsche Ihnen viel Freude und Erkenntnisse!
5 Überblick über die Kennzahlen
skim(movies)| Name | movies |
| Number of rows | 58788 |
| Number of columns | 25 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 23 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| title | 0 | 1 | 1 | 121 | 0 | 56007 | 0 |
| mpaa | 0 | 1 | 0 | 5 | 53864 | 5 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| X | 0 | 1.00 | 29394.50 | 16970.78 | 1 | 14697.75 | 29394.5 | 44091.25 | 58788.0 | ▇▇▇▇▇ |
| year | 0 | 1.00 | 1976.13 | 23.74 | 1893 | 1958.00 | 1983.0 | 1997.00 | 2005.0 | ▁▁▃▃▇ |
| length | 0 | 1.00 | 82.34 | 44.35 | 1 | 74.00 | 90.0 | 100.00 | 5220.0 | ▇▁▁▁▁ |
| budget | 53573 | 0.09 | 13412513.25 | 23350084.93 | 0 | 250000.00 | 3000000.0 | 15000000.00 | 200000000.0 | ▇▁▁▁▁ |
| rating | 0 | 1.00 | 5.93 | 1.55 | 1 | 5.00 | 6.1 | 7.00 | 10.0 | ▁▃▇▆▁ |
| votes | 0 | 1.00 | 632.13 | 3829.62 | 5 | 11.00 | 30.0 | 112.00 | 157608.0 | ▇▁▁▁▁ |
| r1 | 0 | 1.00 | 7.01 | 10.94 | 0 | 0.00 | 4.5 | 4.50 | 100.0 | ▇▁▁▁▁ |
| r2 | 0 | 1.00 | 4.02 | 5.96 | 0 | 0.00 | 4.5 | 4.50 | 84.5 | ▇▁▁▁▁ |
| r3 | 0 | 1.00 | 4.72 | 6.45 | 0 | 0.00 | 4.5 | 4.50 | 84.5 | ▇▁▁▁▁ |
| r4 | 0 | 1.00 | 6.37 | 7.59 | 0 | 0.00 | 4.5 | 4.50 | 100.0 | ▇▁▁▁▁ |
| r5 | 0 | 1.00 | 9.80 | 9.73 | 0 | 4.50 | 4.5 | 14.50 | 100.0 | ▇▁▁▁▁ |
| r6 | 0 | 1.00 | 13.04 | 10.98 | 0 | 4.50 | 14.5 | 14.50 | 84.5 | ▇▂▁▁▁ |
| r7 | 0 | 1.00 | 15.55 | 11.59 | 0 | 4.50 | 14.5 | 24.50 | 100.0 | ▇▃▁▁▁ |
| r8 | 0 | 1.00 | 13.88 | 11.32 | 0 | 4.50 | 14.5 | 24.50 | 100.0 | ▇▃▁▁▁ |
| r9 | 0 | 1.00 | 8.95 | 9.44 | 0 | 4.50 | 4.5 | 14.50 | 100.0 | ▇▁▁▁▁ |
| r10 | 0 | 1.00 | 16.85 | 15.65 | 0 | 4.50 | 14.5 | 24.50 | 100.0 | ▇▃▁▁▁ |
| Action | 0 | 1.00 | 0.08 | 0.27 | 0 | 0.00 | 0.0 | 0.00 | 1.0 | ▇▁▁▁▁ |
| Animation | 0 | 1.00 | 0.06 | 0.24 | 0 | 0.00 | 0.0 | 0.00 | 1.0 | ▇▁▁▁▁ |
| Comedy | 0 | 1.00 | 0.29 | 0.46 | 0 | 0.00 | 0.0 | 1.00 | 1.0 | ▇▁▁▁▃ |
| Drama | 0 | 1.00 | 0.37 | 0.48 | 0 | 0.00 | 0.0 | 1.00 | 1.0 | ▇▁▁▁▅ |
| Documentary | 0 | 1.00 | 0.06 | 0.24 | 0 | 0.00 | 0.0 | 0.00 | 1.0 | ▇▁▁▁▁ |
| Romance | 0 | 1.00 | 0.08 | 0.27 | 0 | 0.00 | 0.0 | 0.00 | 1.0 | ▇▁▁▁▁ |
| Short | 0 | 1.00 | 0.16 | 0.37 | 0 | 0.00 | 0.0 | 0.00 | 1.0 | ▇▁▁▁▂ |
Der skim-Befehl zeigt uns auch die fehlenden Werte an.
6 Fehlende Werte
Wichtig sind oft die Anzahl der fehlenden Werte, darum schauen wir da noch einmal genauer hin (wobei wir das oben mit skim() eigentlich auch schon gesehen haben).
Man könnte jetzt für jede Spalte nach der Anzahl von NA suchen:
movies %>%
summarise(budget_na = sum(is.na(budget)))
#> budget_na
#> 1 53573Oder gleich über alle Spalten hinweg suchen:
movies %>%
summarise(across(everything(), ~ sum(is.na(.))))
#> X title year length budget rating votes r1 r2 r3 r4 r5 r6 r7 r8 r9 r10 mpaa
#> 1 0 0 0 0 53573 0 0 0 0 0 0 0 0 0 0 0 0 0
#> Action Animation Comedy Drama Documentary Romance Short
#> 1 0 0 0 0 0 0 0Der Code heißt sinngemäß etwa:
Fasse zusammen (summarise) und zwar quer durch (across) alle Spalten (everything). Und zwar sollst du so zusammenfassen: Verwende die Funktion (~) “summiere alls fehlenden Werte (is.na)”
Der Punkt bei ~ sum(is.na(.)) meint “alle angesprochenen Spalten”, in diesem Fall sind das alle.
Aha, beim Budget fehlen uns viele Informationen, eigentlich ein Großteil der Informationen:
53573/nrow(movies)
#> [1] 0.9112914Wir stehen also vor einer schwierigen Entscheidung: Wenn wir budget nutzen möchten, können wir ca. 91% der übrigen Variablen nicht für die Vorhersage nutzen.
7 Verteilung der Output-Variablen
Die Output-Variable ist die Variable, die uns besonders interessiert. Ihre Werte wollen wir vorhersagen. Grund genug, uns diese Variable genauer anzuschauen.
movies %>%
ggplot() +
aes(x = rating) +
geom_histogram()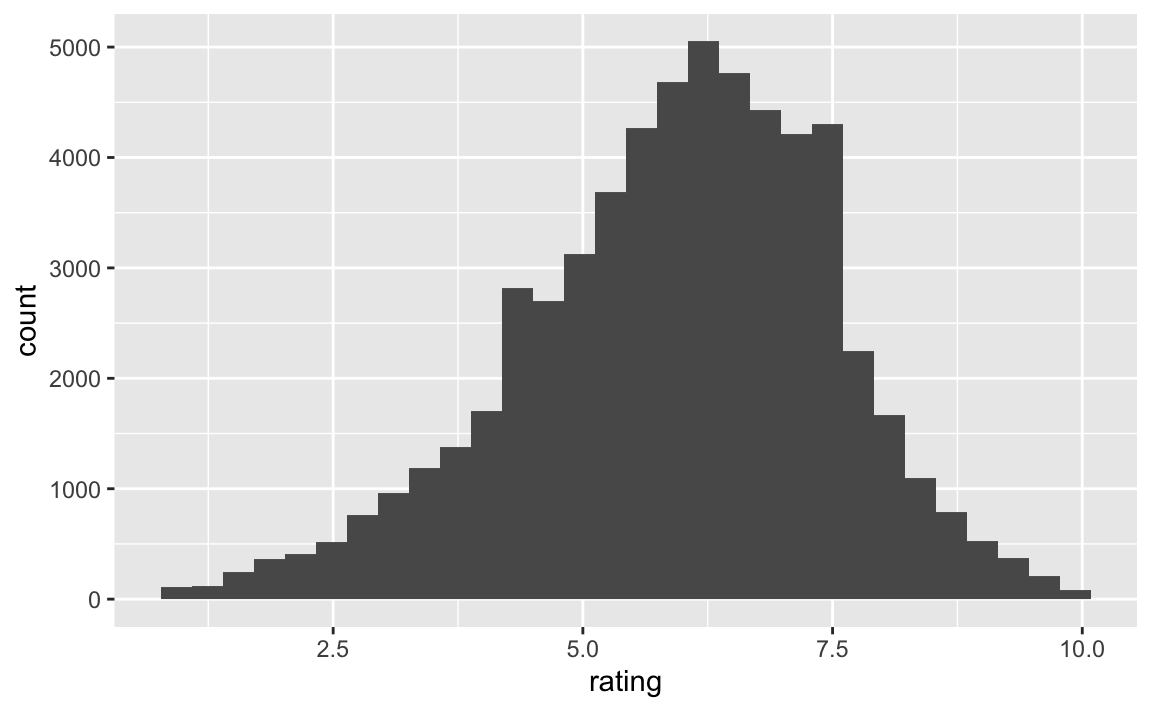
Übrigens kann man aes() auch in den ggplot()-Befehl wickeln:
movies %>%
ggplot(aes(x = rating)) +
geom_histogram()
Das ist das gleiche Ergebnis wie darüber.
Nützlich ist auch, wenn man eine Dichtekurve über das Histogramm legt:
movies %>%
ggplot(aes(x = rating)) +
geom_histogram(aes(y = stat(density))) +
geom_density(col = "red")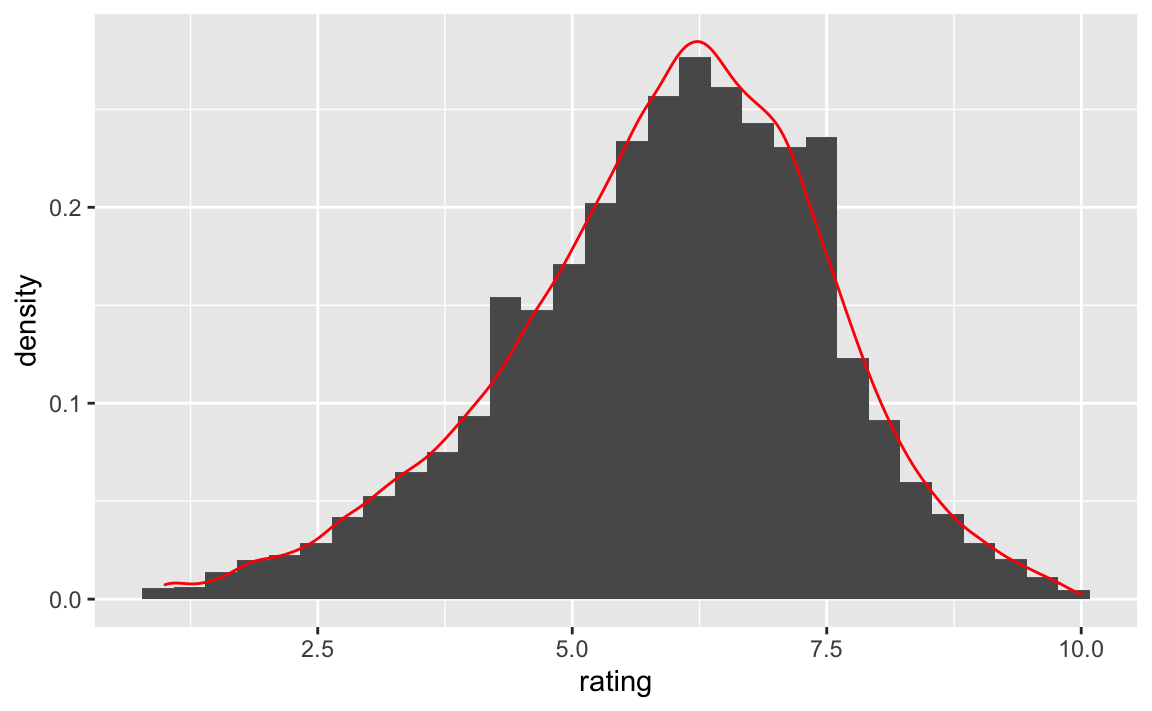
Hier weisen wir der Y-Achse die Dichte (Wahrscheinlichkeit) der jeweiligen Werte auf der X-Achse (d.h. von Rating) zu. Das Histogramm soll also als “Balkenhöhen” der relativen Wahrscheinlichkeit der Balken entsprechen. Das ist im Prinzip das, was das Dichtediagramm zeigt.
Das Rating ist relativ normalverteilt. Das ist kaum überraschend, denn das Antwortformat von 1-10 erlaubt kaum Extremwerte und suggeriert damit eine Mitte. Ob damit die echte, psychologische Dimension “wie gut finde ich den Film” (“Gefallen”) gemessen wird, steht auf einem anderen Blatt. Etwas Skepsis ist berechtigt. Wenn aber unsere Operationalisierung von Gefallen supoptimal ist, also verrauscht, so brauchen wir nicht erwarten, dass unsere Vorhersagen spitze sein werden.
8 Verteilung der Input-Variablen
So könnte man alle Verteilungen mit einem Aufruf darstellen:
movies %>%
mutate(across(where(is.integer), as.numeric)) %>% # Integervariable als numerisch deklarieren
select(where(is.numeric)) %>% # alle numerischen Variablen auswählen
pivot_longer(everything(), names_to = "variable") %>% # auf langes Format pivotieren
ggplot(aes(x = value)) +
geom_histogram() +
facet_wrap(~ variable, scales = "free")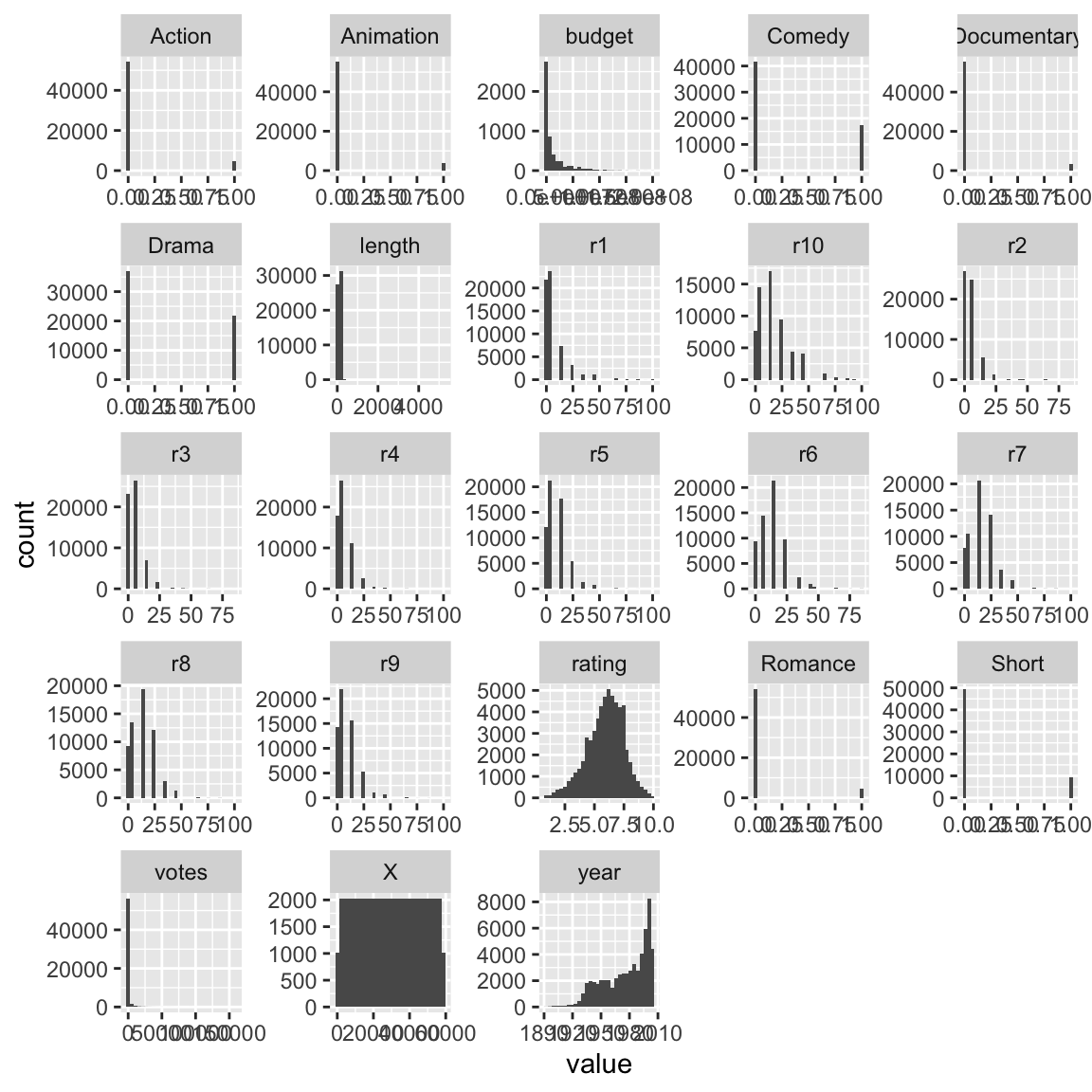
Auf Deutsch übersetzt:
Hey R, nimm den Datensatz “movies” UN DANN
mutiere durch alle Spalten, wo die Variable vom Typ Integer ist, zum Typ numerisch UND DANN
wähle alle Spalten, wo sich der Typ numerisch findet UND DANN pivotiere die Tabelle ins Lang-Format UND DANN Eröffne einen GG-Plot UND DANN Male ein Histogramm UND DANN Male Facetten, nämlich für jede Variable eine.
Oder so:
movies %>%
mutate(across(where(is.integer), as.numeric)) %>%
select(where(is.numeric)) %>%
map( ~ {ggplot(movies, aes(x = .)) + geom_density()})9 Explorative Analyse
Hier sind beispielhaft einige explorativen Analysen dargestellt.
movies %>%
ggplot() +
aes(x = budget, y = rating) +
geom_point(alpha = .2)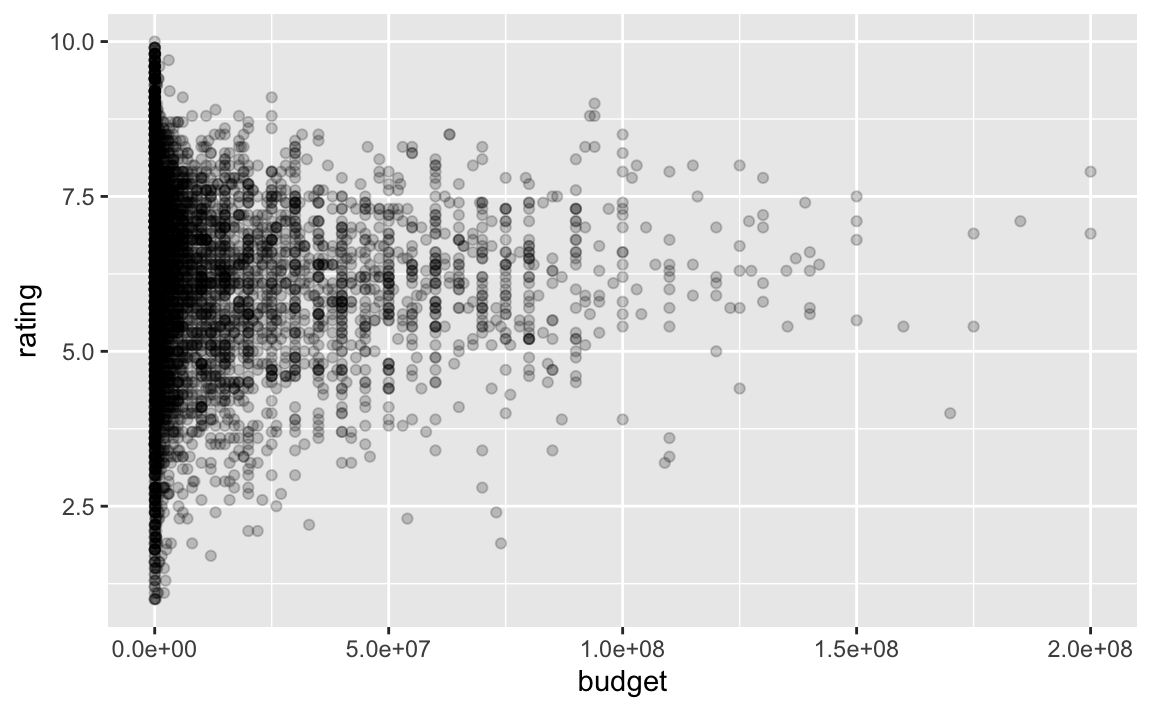
10 Budget logarithmieren
Man sieht eine deutliche Konzentration im unteren Budget-Bereich. Das spricht für eine Transformation, um den Bereich zu “strecken”.
movies %>%
mutate(budget_log10 = log10(budget)) -> movies2Dafür entfernen wir jetzt die ursprüngliche Variable budget.
movies2 %>%
select(budget_log10, everything()) %>% # "budget_log10" als erste Spalte
select(-budget) -> movies2Logarithmiert man die Zahl 0, so kommt -Inf heraus. Das ist keine Zahl und macht daher Probleme. Darum müssen wir uns noch kümmern.
movies2 %>%
filter(!is.nan(budget_log10)) %>%
filter(!is.infinite(budget_log10)) -> movies2aBetrachten wir das Streudiagramm noch einmal. Bei der Gelegenheit fügen wir einen “rollenden Mittelwert” hinzu (“Smoother”). Und wir ergänzen die univariaten Verteilungen der beiden Variablen.
movies2a %>%
ggplot() +
aes(x = budget_log10, y = rating) +
geom_point(alpha = .2) +
geom_smooth() +
geom_rug()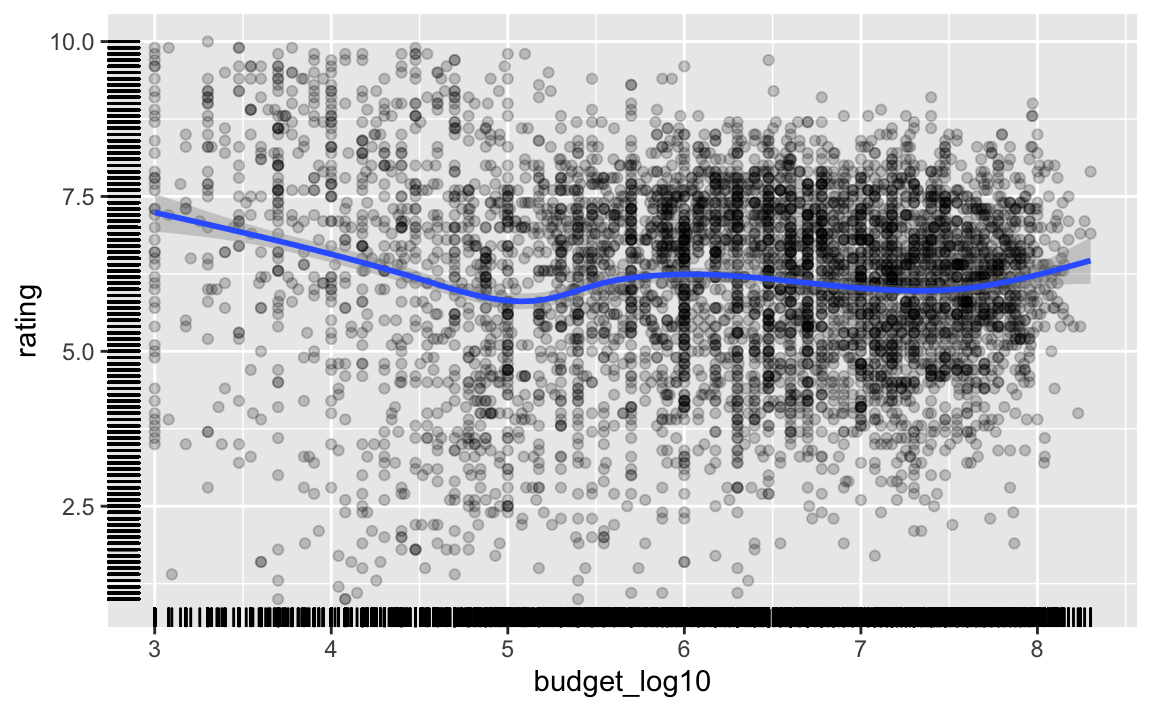
Hier lässt sich vage ein linearer (schwacher) Trend erkennen.
Die univariate Verteilung wird nur schlecht verdeutlicht durch die “Striche” auf den Achsen (geom_rug). Hier müssen wir uns noch etwas Schöneres überlegen.
movies2a %>%
ggscatterstats(x = budget_log10, y = rating)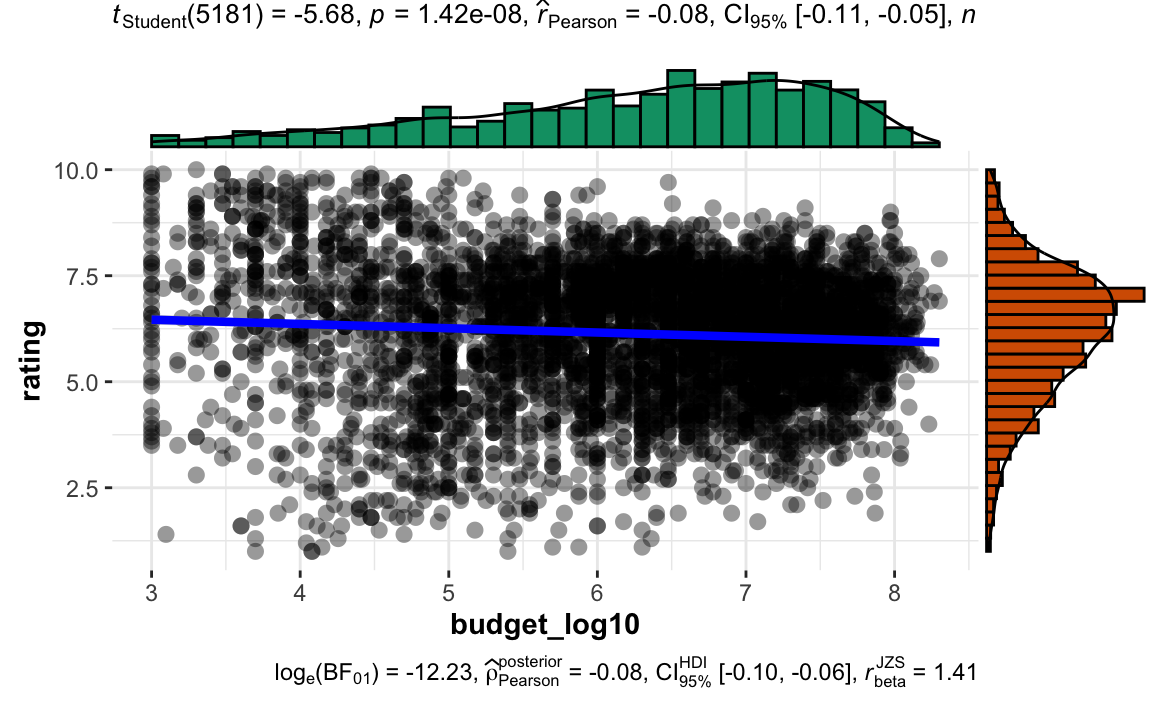
Hier findet sich weitere Erklärung zu diesem Diagramm.
Vielleicht unterscheidet sich dieser Zusammenhang nach dem Genre?
Dazu müssen wir den Datensatz umbauen.
11 Datensatz umbauen (pivotieren): Moderierender Effekt von Genre
movies2a %>%
select(budget_log10, rating, Action:Short) %>%
pivot_longer(cols = Action:Short,
names_to = "genre") %>%
filter(value == 1) -> movies2_longMit pivot_longer() pivotieren wir den Datensatz von der Breit- in die Langform (letzere wird auch als tidy bezeichnet).
Mit filter(value == 1) filtern wir nur die Fälle, die einem Genre zugehören. Probieren Sie mal aus, was passiert, wenn Sie diese Zeile löschen.
Anstelle von Punkten stellen wir jetzt den Zusammenhang mit “Fliesen” dar. Je heller die Fliese, desto mehr Punkte finden sich an dieser Stelle.
Den Zusammenhang teilen wir nach Genre auf, denn das ist die Frage, die wir gerade aufgeworfen hatten.
movies2_long %>%
ggplot() +
aes(x = budget_log10, y = rating) +
geom_bin2d() +
facet_wrap(~ genre) +
geom_smooth() +
scale_fill_viridis_c()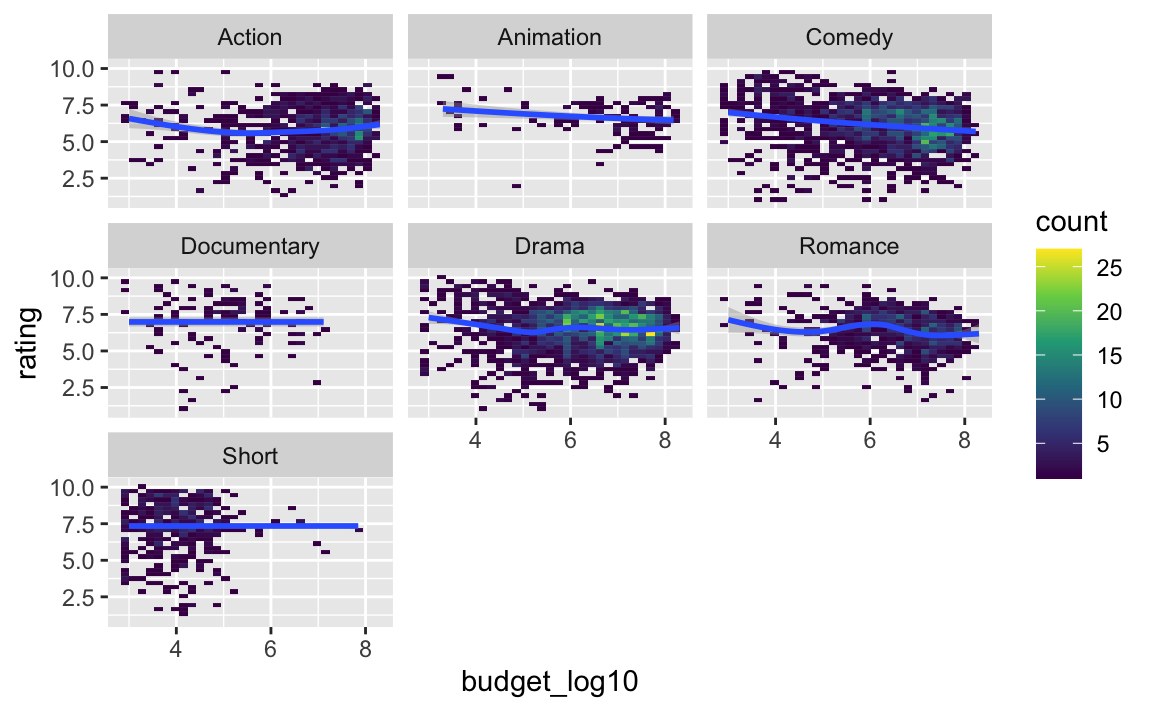
Mit scale_fill_viridis_c() haben wir noch ein schickeres Farbschema ausgewählt. 🏋️ Lassen Sie mal diese Zeile weg und vergleichen Sie das Ergebnis.
👉 Insgesamt scheinen die Zusammenhänge in allen Genres ähnlich zu sein. Das heißt mit anderen Worten, dass wir keine/kaum Evidenz gefunden haben (in dieser Analyse), dass genre den Zusammenhang von Budget und Rating moderieren würde.
12 Korrelation zwischen den Gruppen
movies2_long %>%
drop_na(budget_log10, rating) %>%
group_by(genre) %>%
summarise(cor_group = cor(budget_log10, rating))
#> # A tibble: 7 x 2
#> genre cor_group
#> <chr> <dbl>
#> 1 Action 0.0304
#> 2 Animation -0.205
#> 3 Comedy -0.202
#> 4 Documentary -0.0507
#> 5 Drama -0.0402
#> 6 Romance -0.161
#> 7 Short 0.0096613 Einfluss von Genre
Aber hat das Genre vielleicht einen generellen Effekt auf die Beurteilung? Werden vielleicht Actionfile generell besser bewertet als Kurzfilme?
movies2_long %>%
ggplot() +
aes(x = genre, y = rating) +
geom_boxplot()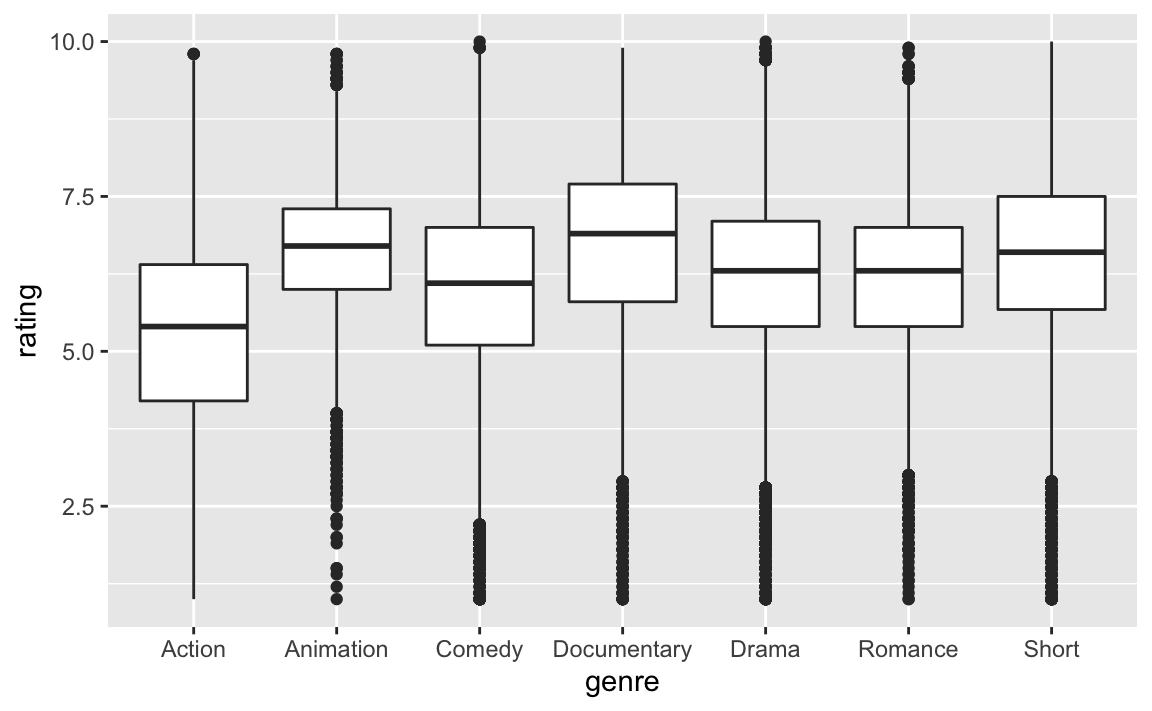
movies2_long %>%
filter(value == 1) %>%
drop_na(rating, genre) %>%
group_by(genre) %>%
summarise(rating_group_md = median(rating))
#> # A tibble: 7 x 2
#> genre rating_group_md
#> <chr> <dbl>
#> 1 Action 5.4
#> 2 Animation 6.7
#> 3 Comedy 6.1
#> 4 Documentary 6.9
#> 5 Drama 6.3
#> 6 Romance 6.3
#> 7 Short 6.6Da scheint’s keine (starken) statistischen Abhängigkeiten zu geben.
14 Datensatz vereinfachen
Die Variable zum Titel ist ohne weitere Bearbeitung kaum nützlich (Stichwort “Feature Engineering”); besser wir entfernen sie der Einfachheit halber.
movies2a %>%
select(-title) -> movies2aUm die Fallstudie einfach zu halten, entfernen wir auch die Bewertungsperzentil-Variablen:
movies2a %>%
select(-c(r1:r10)) -> movies2aDie Variable mpaa sieht auch komisch aus. Wie viele unterschiedliche (distinkte) Werte gibt es?
movies2a %>%
summarise(n_distinct(mpaa))
#> n_distinct(mpaa)
#> 1 5Fünf.
Und wie viele fehlende Werte?
movies2a %>%
summarise(sum(is.na(mpaa)))
#> sum(is.na(mpaa))
#> 1 0Moment, ich habe doch viele leere Zellen gesehen … Vielleicht so:
movies2a %>%
filter(mpaa == "") %>%
nrow() / nrow(movies)
#> [1] 0.9156971Über 90% fehlende Werte also. Besser wir entfernen diese Variable.
movies2a %>%
select(-mpaa) -> movies2a15 Datensatz aufteilen (Train- und Test)
Möchte man eine Vorhersage machen, gehört es zum guten Ton, den Datensatz in einen Train- und einen Test-Teil aufzuteilen. Mit dem Train-Datensatz kann man nach Herzenslust rumbasteln (modellieren); der Test-Datensatz kommt nur einmal zum Schluss zum Einsatz, um die Güte des (besten) Modells zu überprüfen.
Vielen Modelle können keine fehlenden Werte verdauen; daher entfernen wir hier jetzt pauschal alle fehlenden Werte.
movies2a %>%
drop_na() -> movies2_nona # "no NA" soll das heißenWie viele Zeilen bleiben uns?
nrow(movies2_nona)
#> [1] 5183Das ist schon schmerzlich. Ob das eine gute Idee war? Naja, bleiben wir erstmal auf dieser Route.
set.seed(123)
movies2_split <- initial_split(movies2_nona, prop = 0.7)
movies2_train <- analysis(movies2_split)
movies2_test <- assessment(movies2_split)
dim(movies2_train)
#> [1] 3628 13Zum Vergleich, die Zeilenzahl im gesamten Datensatz:
dim(movies)
#> [1] 58788 25Gibt es jetzt noch fehlende Werte im Train- oder Test-Datensatz?
is.na(movies2_train) %>% sum()
#> [1] 0Ok; keine fehlenden Werte mehr.
16 Modell 0 (“Nullmodell”)
Im Folgenden werden wir einige Modelle aufstellen und diese dann vergleichen. Zu Referenzzwecken erstellen wir zuerst ein “Nullmodell”, das null (keine) Prädiktoren beinhaltet. Mit diesem Modell vergleichen wir dann die folgenden Modelle.
m0 <- lm(rating ~ 1, data = movies2_train)Wir nehmen lieben nicht die “Langform” (movies3), da dort die Beobachtungseinheit nicht mehr ein Film ist, im Gegensatz zur Tabelle movies2.
Schauen wir uns die Ergebnisse an:
summary(m0)
#>
#> Call:
#> lm(formula = rating ~ 1, data = movies2_train)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -5.1275 -0.9275 0.1725 1.0725 3.7725
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 6.12751 0.02565 238.9 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.545 on 3627 degrees of freedomDer Output ist nicht “aufgeräumt”; schöner wäre eine Ausgabe in Form eines Dataframes.
Hier die Modellkoeffienten in “tidy” Form; in diesem Fall nur der Achsenabschnitt (Intercept):
tidy(m0)
#> # A tibble: 1 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 6.13 0.0256 239. 0Und die Modellgüte (“model fit”):
glance(m0)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0 1.54 NA NA NA -6726. 13455. 13468.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>\(R^2\) ist hier per Definition gleich Null.
Die Struktur des lm-Objekts kann man sich so anschauen:
#> List of 11
#> $ coefficients : Named num 6.13
#> ..- attr(*, "names")= chr "(Intercept)"
#> $ residuals : Named num [1:3628] -1.328 -0.328 0.172 0.972 1.272 ...
#> ..- attr(*, "names")= chr [1:3628] "2463" "2511" "2227" "526" ...
#> $ effects : Named num [1:3628] -369.077 -0.306 0.194 0.994 1.294 ...
#> ..- attr(*, "names")= chr [1:3628] "(Intercept)" "" "" "" ...
#> $ rank : int 1
#> $ fitted.values: Named num [1:3628] 6.13 6.13 6.13 6.13 6.13 ...
#> ..- attr(*, "names")= chr [1:3628] "2463" "2511" "2227" "526" ...
#> $ assign : int 0
#> $ qr :List of 5
#> ..$ qr : num [1:3628, 1] -60.2329 0.0166 0.0166 0.0166 0.0166 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : chr [1:3628] "2463" "2511" "2227" "526" ...
#> .. .. ..$ : chr "(Intercept)"
#> .. ..- attr(*, "assign")= int 0
#> ..$ qraux: num 1.02
#> ..$ pivot: int 1
#> ..$ tol : num 1e-07
#> ..$ rank : int 1
#> ..- attr(*, "class")= chr "qr"
#> $ df.residual : int 3627
#> $ call : language lm(formula = rating ~ 1, data = movies2_train)
#> $ terms :Classes 'terms', 'formula' language rating ~ 1
#> .. ..- attr(*, "variables")= language list(rating)
#> .. ..- attr(*, "factors")= int(0)
#> .. ..- attr(*, "term.labels")= chr(0)
#> .. ..- attr(*, "order")= int(0)
#> .. ..- attr(*, "intercept")= int 1
#> .. ..- attr(*, "response")= int 1
#> .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv>
#> .. ..- attr(*, "predvars")= language list(rating)
#> .. ..- attr(*, "dataClasses")= Named chr "numeric"
#> .. .. ..- attr(*, "names")= chr "rating"
#> $ model :'data.frame': 3628 obs. of 1 variable:
#> ..$ rating: num [1:3628] 4.8 5.8 6.3 7.1 7.4 5.6 7.5 4 6.2 7.5 ...
#> ..- attr(*, "terms")=Classes 'terms', 'formula' language rating ~ 1
#> .. .. ..- attr(*, "variables")= language list(rating)
#> .. .. ..- attr(*, "factors")= int(0)
#> .. .. ..- attr(*, "term.labels")= chr(0)
#> .. .. ..- attr(*, "order")= int(0)
#> .. .. ..- attr(*, "intercept")= int 1
#> .. .. ..- attr(*, "response")= int 1
#> .. .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv>
#> .. .. ..- attr(*, "predvars")= language list(rating)
#> .. .. ..- attr(*, "dataClasses")= Named chr "numeric"
#> .. .. .. ..- attr(*, "names")= chr "rating"
#> - attr(*, "class")= chr "lm"17 Modell 1: budget_log10
movies2_train %>%
drop_na(budget_log10, rating) %>%
lm(rating ~ budget_log10, data = .) -> m1Upps, ein Fehler, was ist passiert? Die Fehlermeldung sagt uns, es gäbe unendliche Werte in unseren Daten. Gut, eine brave Maschine weiß dann nicht genau, was sie tun soll …
movies2_train %>%
select(budget_log10, rating) %>%
filter(budget_log10 == -Inf)
#> [1] budget_log10 rating
#> <0 rows> (or 0-length row.names)Da haben wir die Schuldigen. Eine Log-Transformation von null Budget liefert:
log10(0)
#> [1] -InfGenau wie:
log(0)
#> [1] -Inf18 Unendliche Werte entfernen
Diese Null-Budgets hätten wir entfernen müssen. Na gut, dann machen wir es jetzt.
movies2_train %>%
filter(budget_log10 != -Inf) -> movies2_trainEvtl. wäre es besser, in einen neuen Datensatz abzuspeichern. Das ist manchmal eine schwierige Frage.
movies2_train %>%
lm(rating ~ budget_log10, data = .) -> m119 Model 1 Ergebnisse
tidy(m1)
#> # A tibble: 2 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 6.73 0.135 49.8 0
#> 2 budget_log10 -0.0962 0.0213 -4.52 0.00000640Die Modellgüte sieht so aus:
glance(m1)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.00560 0.00533 1.54 20.4 0.00000640 1 -6715. 13437. 13455.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Also peinlich schlecht.
20 Anzahl der Stimmen (votes)
Vielleicht lässt die Anzahl der abgegebenen Stimmen (votes) einen Rückschluss auf die spätere Beurteilung zu? Nach dem Motto: Wenn viele Leute eine Beurteilung abgeben, dann sind die Gemüter erhitzt und der Film muss spalten. Wobei diese Behauptung eigentlich nichts über den Mittelwert der Beurteilung aussagt, sondern über die Streuung. Aber schauen wir einfach mal.
p1 <- movies2_train %>%
ggplot(aes(x = votes)) +
geom_histogram() +
labs(title = "Datensatz: movies2_train")
p1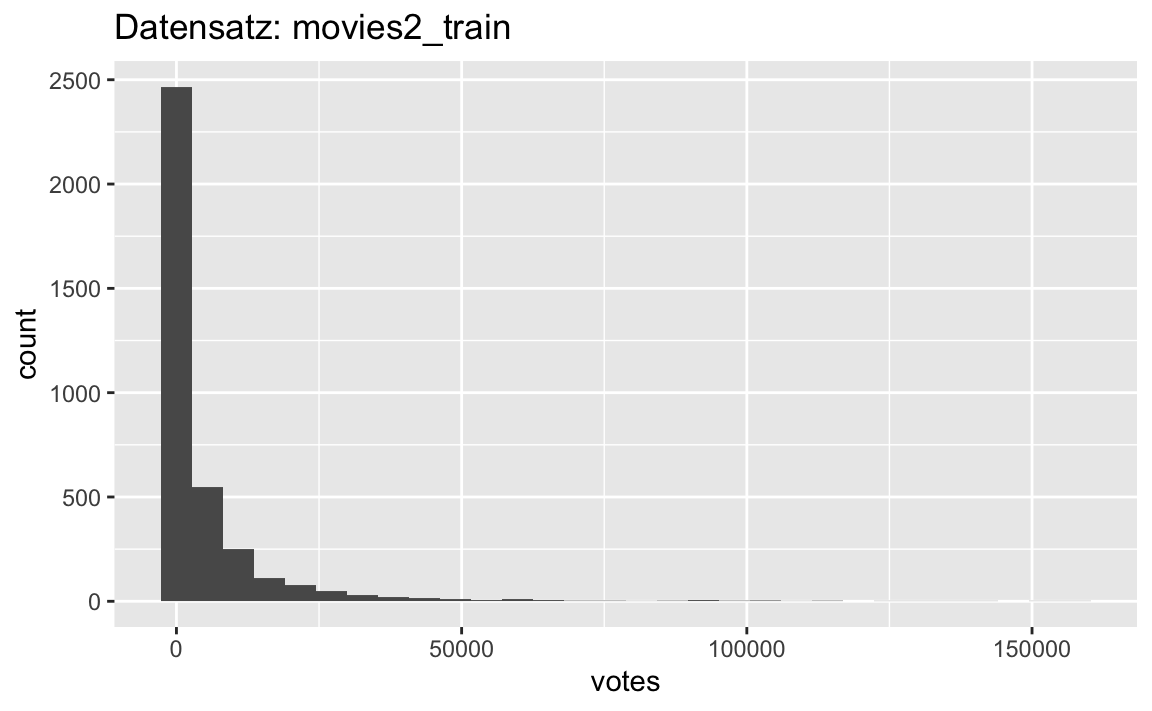
Ein ggplot-Diagramm ist auch nur ein Objekt, wie jedes andere R-Objekt auch. Daher kann man es auch in einer Variablen speichern. Ruft man diese Variable (p1, p wie plot) auf, so wird das Diagramm gezeigt.
Oha! Das ist richtig schön schief.
Vergleichen wir mal, ob es Unterschiede in der Verteilung gibt, in den verschiedenen Varianten des Datensatzes.
p2 <- movies %>%
ggplot(aes(x = votes)) +
geom_histogram() +
labs(title = "Datensatz: movies")
p3 <- movies2_test %>%
ggplot(aes(x = votes)) +
geom_histogram() +
labs(title = "Datensatz: movies2_test")Möchte man mehrere Plots zusammenfügen, so kann man das so tun:
plot_grid(p1, p2, p3)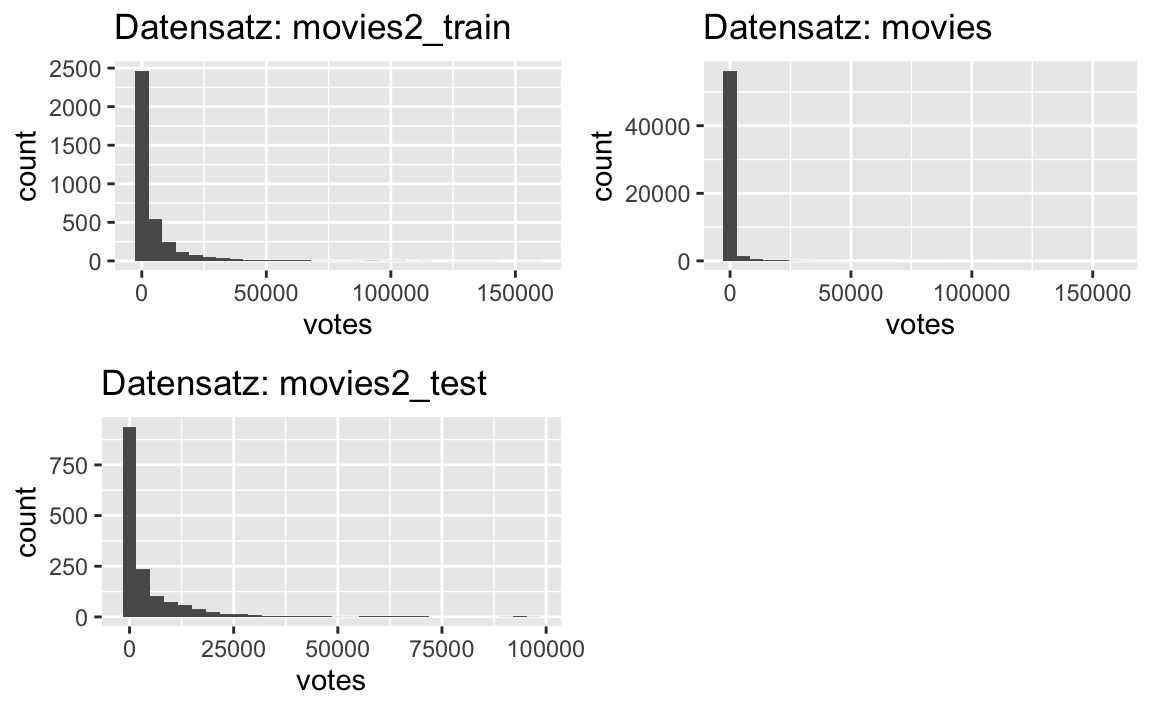
Betrachten wir das Streudiagramm:
movies2_train %>%
ggplot(aes(x = votes, y = rating)) +
geom_point()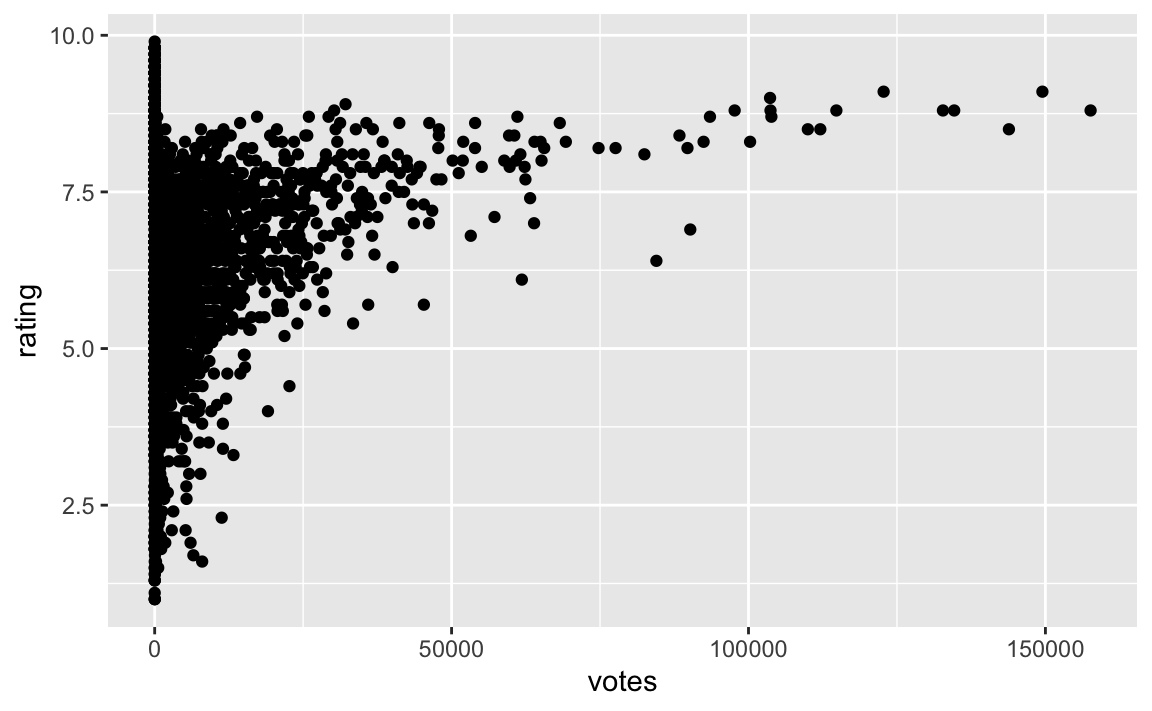
Die Schiefe kann man als Anlass sehen, votes zu logarithmieren.
movies2_train %>%
ggplot(aes(x = log10(votes), y = rating)) +
geom_point(alpha = .4) +
geom_smooth(method = "lm")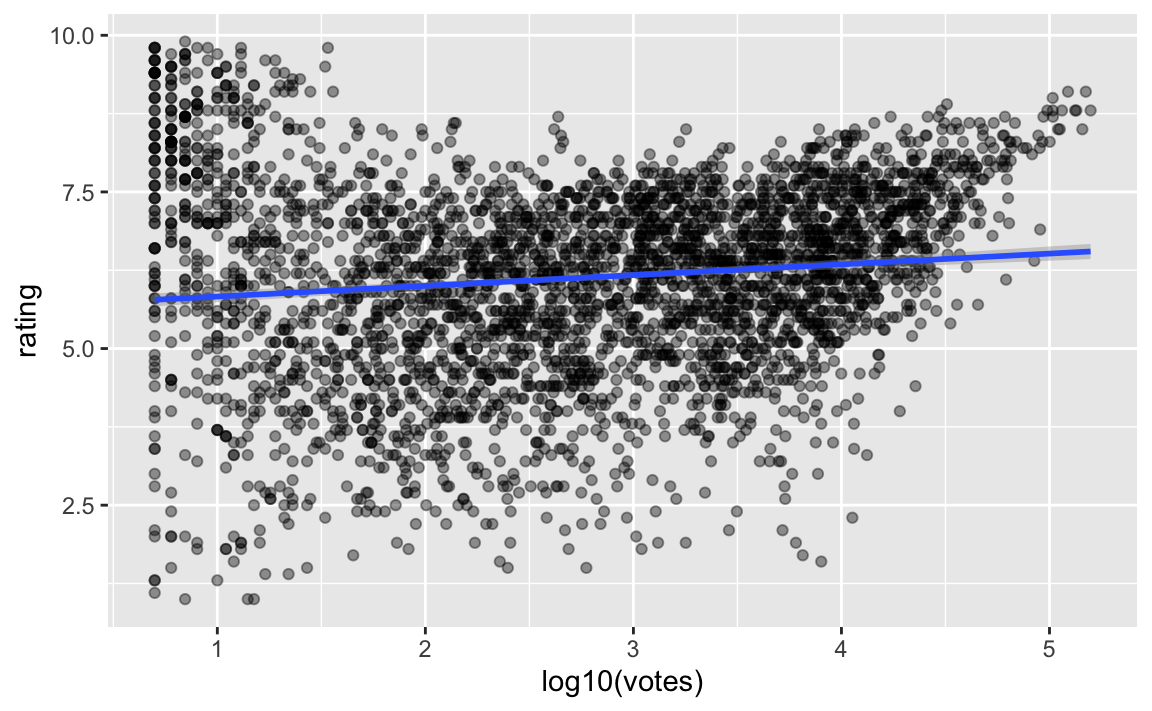 Hier haben wir gleich eine Regressionsgerade in den Punkteschwarm gelegt.
Hier haben wir gleich eine Regressionsgerade in den Punkteschwarm gelegt.
Eine Variante:
movies2_train %>%
ggplot(aes(x = log10(votes), y = rating)) +
geom_point(alpha = .2) +
geom_smooth(method = "lm", color = "red") +
geom_density_2d()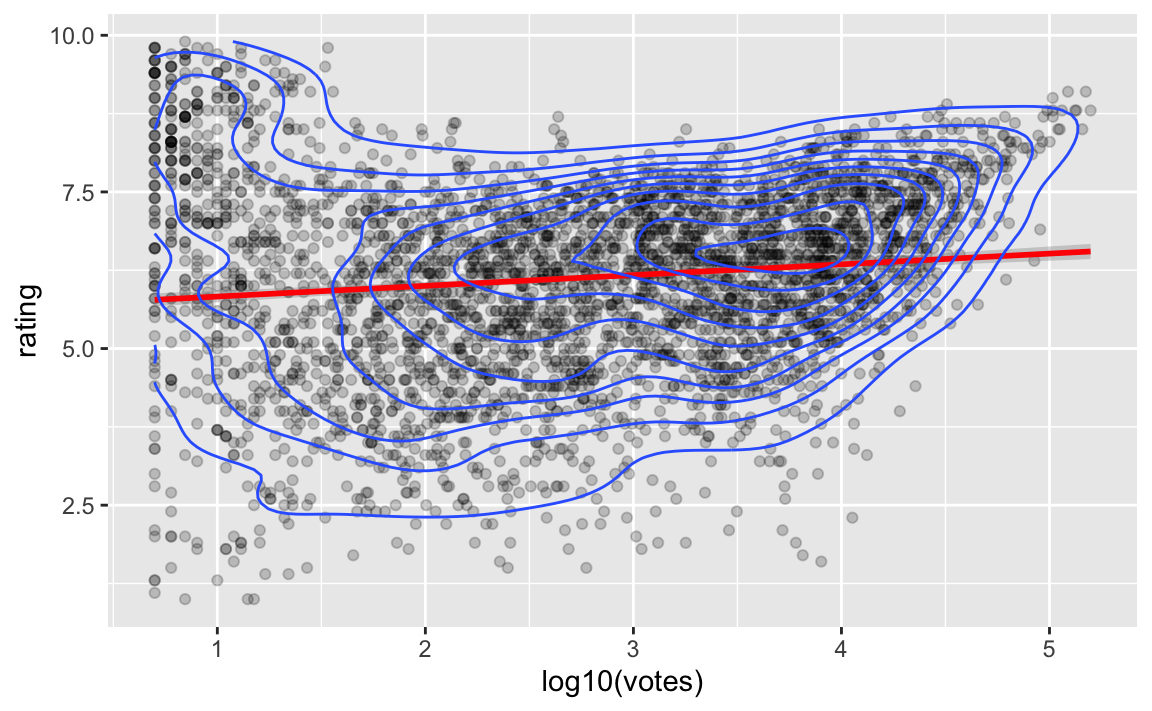
21 Modell 2: Anzahl der Stimmen, linear
Erstellen wir die logarithmierte Version von votes:
movies2_train %>%
mutate(votes_log10 = log10(votes)) %>%
select(-votes) -> movies2_trainmovies2_train %>%
lm(rating ~ votes_log10, data = .) -> m2
m2 %>%
tidy()
#> # A tibble: 2 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 5.66 0.0677 83.6 0
#> 2 votes_log10 0.171 0.0229 7.48 9.37e-14
glance(m2)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.0152 0.0149 1.53 55.9 9.37e-14 1 -6698. 13402. 13420.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Tja. Unsere Erklärungskraft bleibt bescheiden.
22 Modell 3: Anzahl der Stimmen als Polynomialmodell, quadratisch
Betrachtet man das Streudiagramm mit den Anzahl der Stimmen, so könnte man auf die Idee kommen, der Zusammenhang sei durch ein Polynomialmodell gut zu beschreiben.
Probieren wir ein quadratisches Modell (also zweiten Grades):
m3 <- lm(rating ~ I(votes_log10^2) + votes_log10, data = movies2_train)Das I() brauchen wir, weil in der Formel-Schreibweise ein Dach “^” nicht die normale algebraische Bedeutung hat. Mit I wird gesagt, dass die normale algebraische Bedeutung, trotz dem Formelschreibweisenumgebung, gelten soll.
Die Ergebnisse:
tidy(m3)
#> # A tibble: 3 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 8.17 0.132 62.1 0
#> 2 I(votes_log10^2) 0.434 0.0199 21.8 1.79e-99
#> 3 votes_log10 -2.13 0.108 -19.8 5.28e-83glance(m3)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.130 0.129 1.44 270. 4.13e-110 2 -6473. 12955. 12980.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Schon etwas besser.
Schauen wir uns das Polynom 2. Grades einmal an:
movies2_train %>%
ggplot(aes(x = votes_log10, y = rating)) +
geom_point(alpha = .2) +
geom_smooth(method = "lm", se = FALSE,
formula = y ~ poly(x, 2))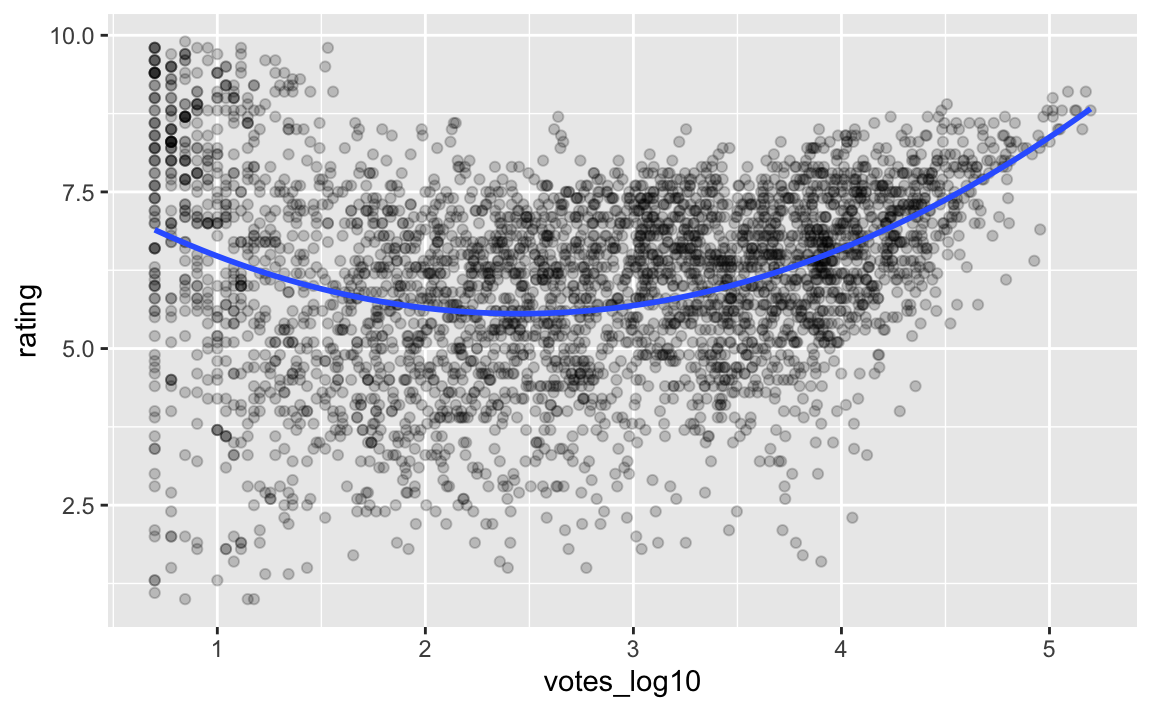
23 Modell 4: Anzahl der Stimmen als Polynomialmodell, 3. Grades
Vielleicht ein Polynom 3. Grades?
movies2_train %>%
ggplot(aes(x = votes_log10, y = rating)) +
geom_point(alpha = .2) +
geom_smooth(method = "lm", se = FALSE,
formula = y ~ poly(x, 3))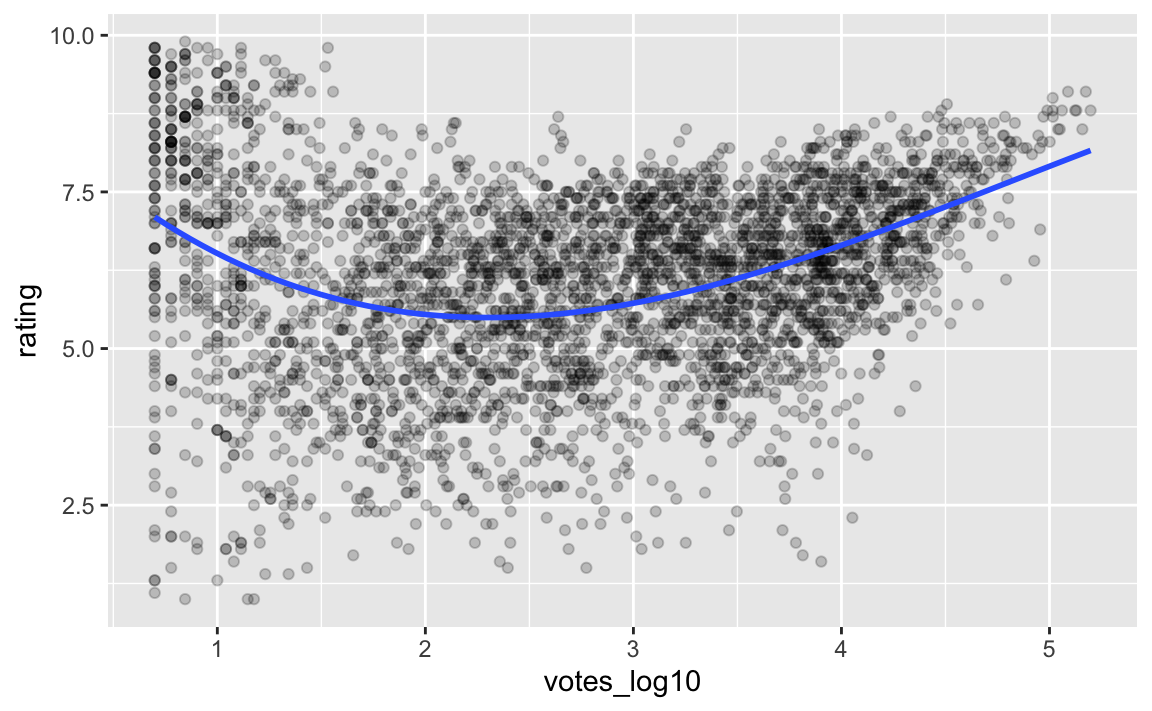
Sieht nicht viel besser aus. Da ist einfach viel Rauschen in den Daten, scheint’s.
m4 <- lm(rating ~ poly(votes_log10, degree = 3),
data = movies2_train)Anstelle die Prädiktoren mit I() kann man auch – einfacher – mit poly() das Polynom vom Grad degree bestimmen.
Die Ergebnisse:
tidy(m4)
#> # A tibble: 4 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 6.13 0.0239 257. 0
#> 2 poly(votes_log10, degree = 3)1 11.5 1.44 7.97 2.11e- 15
#> 3 poly(votes_log10, degree = 3)2 31.5 1.44 21.9 8.00e-100
#> 4 poly(votes_log10, degree = 3)3 -5.56 1.44 -3.86 1.13e- 4
glance(m4)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.133 0.133 1.44 186. 4.52e-112 3 -6466. 12942. 12973.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Es scheint keinen Unterschied zu machen, ob man ein Polynom 2. oder 3. Grades in die Daten anpasst.
24 Korrelationsmatrix (visualisieren)
Vielleicht kann (nur) eine Kombination mehrerer Prädiktoren zu einer genauen Vorhersage führen? Probieren wir es aus.
Zuerst betrachten wir die bivariaten Korrelation.
movies_corr <- correlate(movies2_train) %>%
rearrange() %>% # der Größe nach ordnen
mutate_if(is.numeric, ~ifelse(abs(.) > 0.2, ., NA)) %>%
shave() # redundantes Dreieck abrasieren
fashion(movies_corr)
#> term length budget_log10 votes_log10 Drama Action Romance X year
#> 1 length
#> 2 budget_log10 .64
#> 3 votes_log10 .56 .77
#> 4 Drama .27
#> 5 Action .23 .21
#> 6 Romance
#> 7 X
#> 8 year
#> 9 Comedy -.23
#> 10 Animation
#> 11 rating .22
#> 12 Documentary
#> 13 Short -.71 -.54 -.44
#> Comedy Animation rating Documentary Short
#> 1
#> 2
#> 3
#> 4
#> 5
#> 6
#> 7
#> 8
#> 9
#> 10
#> 11
#> 12
#> 13 .23Diese Zeile mutate_if(is.numeric, ~ifelse(abs(.) > 0.2, ., NA)) heißt grob übersetzt:
Verändere eine Spalte, wenn (if) sie numerisch ist. Und zwar folgendermaßen: wenn der Absolutwert in einer Zelle größer ist als 0.2, dann übernehme ihn, wie er ist (.), ansonsten ersetze durch NA.
Scheuen wir uns nur die Korrelationen mit rating näher an:
movies_corr %>%
select(1, rating)
#> # A tibble: 13 x 2
#> term rating
#> <chr> <dbl>
#> 1 length NA
#> 2 budget_log10 NA
#> 3 votes_log10 NA
#> 4 Drama NA
#> 5 Action NA
#> 6 Romance NA
#> 7 X NA
#> 8 year NA
#> 9 Comedy NA
#> 10 Animation NA
#> 11 rating NA
#> 12 Documentary NA
#> 13 Short 0.233Tja, aus den bivariaten Korrelationen ist nicht viel rauszuholen. Bleibt als Hoffnung:
- nichtlineare Zusammenhänge
- Interaktionen, so dass nur mehrere Variablen gleichzeitig mit der Zielvariablen korrelieren
- dass “Kleinvieh-macht-auch-Mist-Prinzip”: Vielleicht läppert sich ein bisschen Korrelation pro Prädiktor zu einer ansehnlichen Gesamtvorhersagekraft.
Visualisieren wir noch die Korrelationsmatrix:
rplot(movies_corr)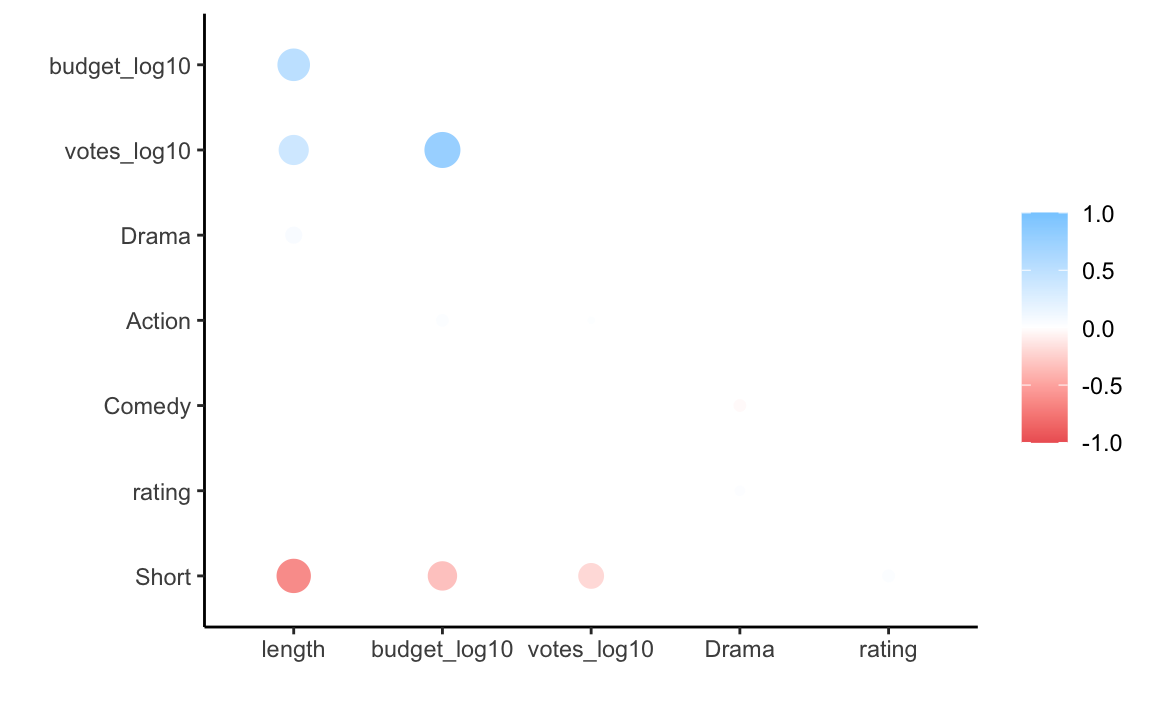
25 Modell 5: Multiple Regression
Untersuchen wir ein Modell, das mehrere Prädiktoren vereint.
m5 <- lm(rating ~ votes_log10 + budget_log10, data = movies2_train)glance(m5)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.0856 0.0851 1.48 170. 3.81e-71 2 -6563. 13135. 13159.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>26 3D-Visualisierung
Verändern wir die Reihenfolge der Spalten, so dass die “wichtigen” Spalten vorne stehen:
movies2_train %>%
select(rating, votes_log10, budget_log10, everything()) -> movies2_trainIn diesem Modell sind 3 Variablen involviert. Eine Visualisierung ist hier schon schwierig. Hier finden sich dazu einige Anregungen.
Das könnte eine Möglichkeit sein:
rsm::contour.lm(m5, votes_log10 ~ budget_log10, image = TRUE)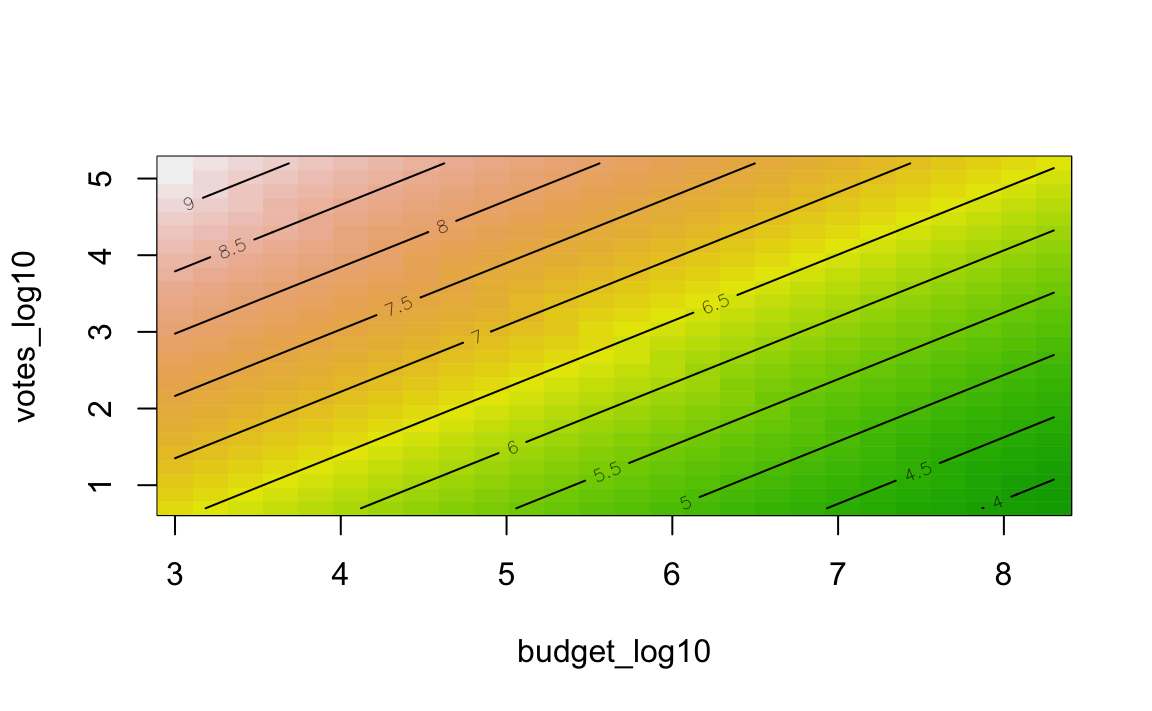
Die Farbe gibt die “Höhe” des Wertes in der Output-Variablen wider.
27 Modell 6: Interaktionsmodell
m6 <- lm(rating ~ votes_log10 + budget_log10 + votes_log10:budget_log10,
data = movies2_train)glance(m6)
#> # A tibble: 1 x 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.116 0.115 1.45 159. 1.06e-96 3 -6502. 13013. 13044.
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>28 Rohe Kraft: Schrittweise Regression
Wir könnten jetzt sagen, wir geben es auf, nach einzelnen netten Prädiktoren zu suchen. Schön wäre natürlich, wir hätten eine Theorie, die uns (kausal) sagt, welche Prädiktoren eine Rolle spielten. In Ermangelung derselben können wir auch rein datengetrieben vorgehen.
Einfach gesprochen sagen wir zu R: “Berechne ein Modell mit einem Prädiktor; dabei probiere aus, welcher Prädiktor zum besten Modell führt. Dann wiederhole das mit 2 Prädiktoren und so weiter bis du zu einem Modell kommst, das alle Prädiktoren beinhaltet. Wenn aber irgendwann die Hinzunahme von einem Prädiktor nicht zu einem besseren Modell führt, dann brich ab.”
Wir brauchen ein Nullmodell, das haben wir oben schon definiert (m0). Hier noch mal:
m0 <- lm(rating ~ 1,
data = movies2_train)Und wir brauchen ein “Vollmodell” (m_all), das alle Prädiktoren beinhaltet.
m_all <- lm(rating ~ .,
data = movies2_train) # kann etwas Zeit brauchenDieses Vorgehen nennt man auch schrittweise (Vorwärts-)Regression.
forward <- step(object = m0,
direction = 'forward',
scope = formula(m_all),
trace = 0) # keine Zwischenschritte zeigenVorsicht! Bei nominalen Variablen mit vielen unterschiedlichen Werten kann diese Berechnung lange dauern.
tidy(forward)
#> # A tibble: 12 x 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 20.7 2.17 9.53 2.82e- 21
#> 2 Short 2.85 0.118 24.2 3.14e-120
#> 3 length 0.0156 0.00112 14.0 3.25e- 43
#> 4 Drama 0.654 0.0482 13.6 4.57e- 41
#> 5 votes_log10 0.570 0.0314 18.2 1.30e- 70
#> 6 budget_log10 -0.407 0.0334 -12.2 1.51e- 33
#> 7 Documentary 1.25 0.145 8.64 8.32e- 18
#> 8 year -0.00797 0.00112 -7.13 1.24e- 12
#> 9 Animation 0.809 0.144 5.61 2.16e- 8
#> 10 Comedy 0.238 0.0495 4.81 1.58e- 6
#> 11 Action -0.212 0.0639 -3.32 9.05e- 4
#> 12 X 0.00000246 0.00000129 1.90 5.77e- 229 Modellselektion (Modellwahl) – anova
Es gibt verschiedene Methoden, um ein hoffentlich bestes Modell auszuwählen.
anova(m0, m2, m3, m4)
#> Analysis of Variance Table
#>
#> Model 1: rating ~ 1
#> Model 2: rating ~ votes_log10
#> Model 3: rating ~ I(votes_log10^2) + votes_log10
#> Model 4: rating ~ poly(votes_log10, degree = 3)
#> Res.Df RSS Df Sum of Sq F Pr(>F)
#> 1 3627 8657.2
#> 2 3626 8525.7 1 131.51 63.517 2.111e-15 ***
#> 3 3625 7534.0 1 991.65 478.969 < 2.2e-16 ***
#> 4 3624 7503.1 1 30.92 14.933 0.0001134 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Eine Varianzanalyse (anova) besteht im Kern aus einem \(F\)-Test. Der F-Test ist so definiert:
\[F =\frac{(TSS-RSS)/p}{RSS/(n-p-1)}\]
Dabei ist TSS die Gesamtstreuung, RSS die Streuung der Residuen; \(n\) die Anzahl der Beobachtungen und \(p\) die Anzahl der Prädiktoren; s. Witten et al. (2013), S. 75 (eq. 3.23).
Man kann diese Formel verwenden, um die Residualstreuung eines einfacheren Modells (\(RSS_0\)) im Vergleich zu einem “verschachtelteren” (komplexeren) Modells (\(RSS\)) zu vergleichen:
\[F =\frac{(RSS_0-RSS)/p}{RSS/(n-p-1)}\]
- Witten et al. (2013), S. 77 (eq. 3.24).
Genau das wird mit anova() angezeigt.
m1 und m2 sind nicht ineinander verschachtelt; m2 ist genau komplex wie m1; daher wird hier kein Test durchgeführt bzw. würden keine Koeffizienten von anova() ausgegeben.
30 Modellselektion (Modellwahl) – Prädiktion
modellist <- list(m0, m1, m2, m3, m4, m5, m6, forward)model_preds <- modellist %>%
map( ~ predict(., movies2_test))
#> Error in eval(predvars, data, env): object 'votes_log10' not foundMit map() wird die angegebene Funktion – predict() auf jedes Element von modellist “gemapt”, zugeordnet oder angewendet also.
Oh, uns fehlen noch die Transformationen im Test-Sample…
movies2_test %>%
mutate(votes_log10 = log10(votes)) -> movies2_testNoch einmal:
model_preds <- modellist %>%
map_dfc( ~ predict(., movies2_test))Schauen wir uns das Ergebnisobjekt an:
glimpse(model_preds)
#> Rows: 1,555
#> Columns: 8
#> $ ...1 <dbl> 6.127508, 6.127508, 6.127508, 6.127508, 6.127508, 6.127508, 6.127…
#> $ ...2 <dbl> 6.018852, 6.082631, 6.145912, 6.217160, 6.217160, 5.964221, 5.988…
#> $ ...3 <dbl> 6.155901, 6.075402, 6.045352, 6.082722, 5.803194, 6.370895, 6.263…
#> $ ...4 <dbl> 5.644215, 5.557038, 5.573610, 5.557045, 6.681743, 6.816318, 6.058…
#> $ ...5 <dbl> 5.666664, 5.503725, 5.495860, 5.510274, 6.798402, 6.834337, 6.145…
#> $ ...6 <dbl> 5.626967, 5.691683, 5.934694, 6.463845, 5.460634, 6.095668, 5.846…
#> $ ...7 <dbl> 5.566329, 5.500739, 5.726260, 6.197511, 5.579736, 6.539594, 6.006…
#> $ ...8 <dbl> 5.471932, 4.930652, 5.367656, 7.209424, 5.365659, 5.318496, 6.798…Eine Tabelle mit 8 Spalten Jede dieser 8 Spalten sind die Vorhersagen für eines der Modelle. Wie gut wohl jeweils die Vorhersagen sind?
Geben wir zuerst schönere Namen an die Spalten:
col_names <- paste0("model", 0:7)
names(model_preds) <- col_namesFügen wir dann die wahren Beurteilungswerte zur Tabelle mit den Vorhersagen hinzu:
model_preds %>%
bind_cols(select(movies2_test, rating)) -> model_predsSchauen wir beispielfhaft einige Modelle in ihren Gütekoeffizienten an:
metrics(model_preds, truth = rating, estimate = model2)
#> # A tibble: 3 x 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 rmse standard 1.53
#> 2 rsq standard 0.0148
#> 3 mae standard 1.20metrics(model_preds, truth = rating, estimate = model3)
#> # A tibble: 3 x 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 rmse standard 1.43
#> 2 rsq standard 0.141
#> 3 mae standard 1.1131 Hm
Wie kommt man jetzt elegant zu dem Modell mit den besten Modellkoeffizienten? Jemand eine gute Idee?
32 Vielleicht so: Vergleich der Modellgüten
Typische Maße der Modellgüte sind RMSE und \(R^2\).
32.1 RMSE
RMSE: Root Mean Squared Error. Grob gesagt: Die mittlere Länge eines Residuums.
Hier ist eine Funktion, die die Modellgüten (RMSE) berechnet:
get_rmse <- function(est) {
rmse <- sqrt(mean((model_preds$rating - est)^2))
}Die Funktion fasst einen Vektor zu einem Skalar zusammen, kann also gut mit summarise() verwendet werden.
Wir wenden die Funktion über alle Spalten hinweg (across everything) an:
model_preds %>%
summarise(across(everything(), get_rmse)) -> model_rmseknitr::kable(model_rmse)| model0 | model1 | model2 | model3 | model4 | model5 | model6 | model7 | rating |
|---|---|---|---|---|---|---|---|---|
| 1.541326 | 1.535519 | 1.529956 | 1.428753 | 1.423921 | 1.468111 | 1.44571 | 1.325001 | 0 |
model_rmse %>%
pivot_longer(cols = everything(),
names_to = "model",
values_to = "rmse") %>%
filter(model != "rating") %>%
ggplot() +
aes(x = reorder(model, -rmse), y = rmse) +
geom_point()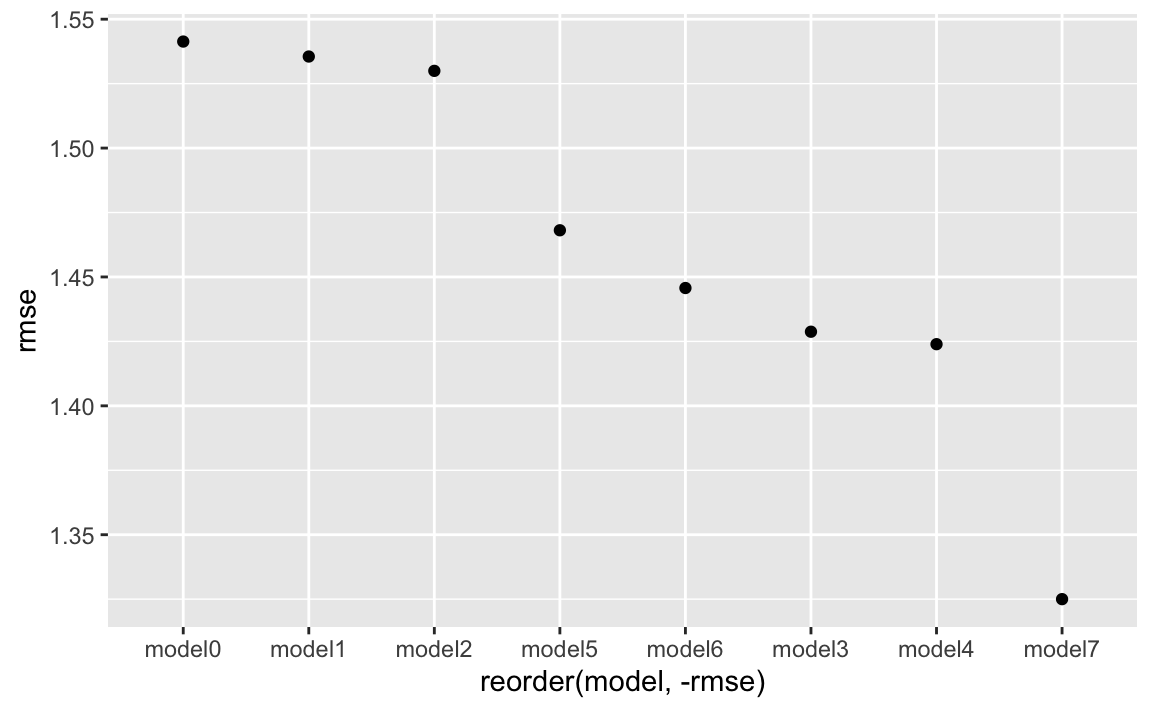
32.2 R-Quadrat
Ein alternatives Maß zu RMSE ist R-Quadrat.
get_r2 <- function(est) {
r2 <- cor(model_preds$rating, est)^2
}model_preds %>%
summarise(across(everything(), get_r2)) -> model_r2
model_r2
#> # A tibble: 1 x 9
#> model0 model1 model2 model3 model4 model5 model6 model7 rating
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 NA 0.00767 0.0148 0.141 0.147 0.0929 0.120 0.262 133 Prüfung der Voraussetzungen
ggplot2::autoplot(forward) + theme_minimal()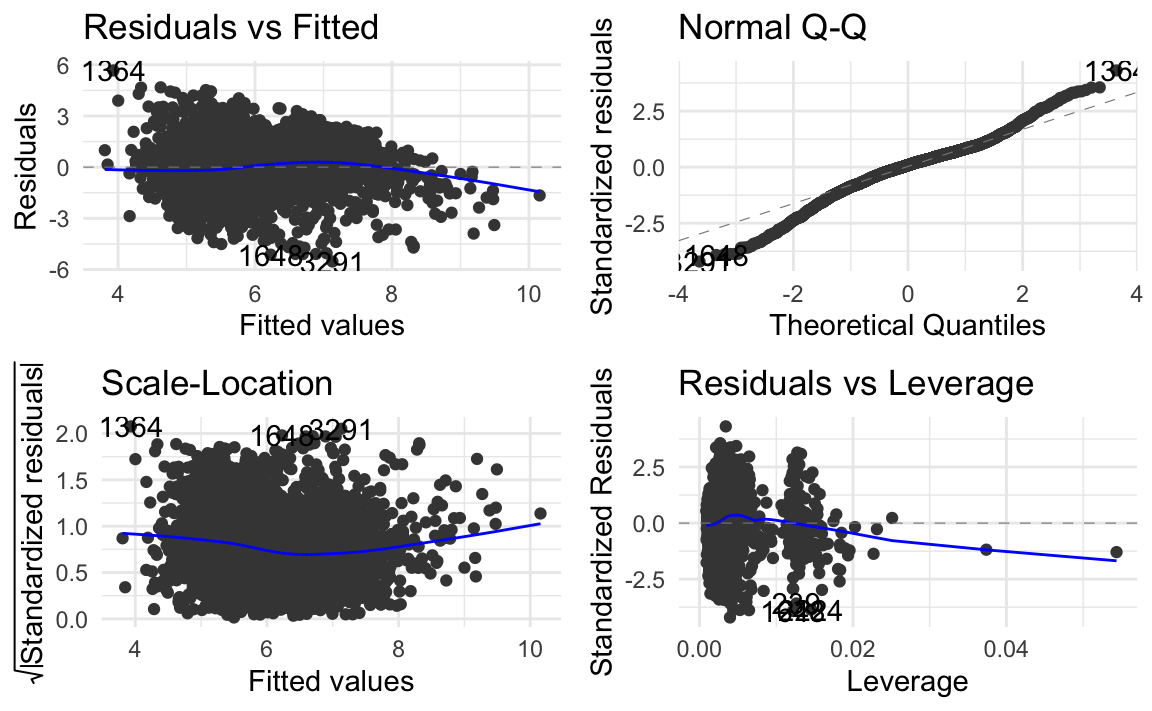
34 Bestes Modell
model_r2 %>%
pivot_longer(everything()) %>%
arrange(-value) %>%
filter(value != 1, value > 0)
#> # A tibble: 7 x 2
#> name value
#> <chr> <dbl>
#> 1 model7 0.262
#> 2 model4 0.147
#> 3 model3 0.141
#> 4 model6 0.120
#> 5 model5 0.0929
#> 6 model2 0.0148
#> 7 model1 0.00767Model 7 ist das Beste! model7 war das Forward-Regressionsmodell.
35 Vorhersagen
Spalte X ist eine ID-Spalte.
movies2_test_pred <-
movies2_test %>%
add_predictions(forward) %>%
select(pred, rating, ID = X)Da wir in diesem Fall die Zielwerte (die “Lösung”) in den Testwerten kennen, können wir die Modellgüte berechnen. In der “echten Welt” geht das normalerweise nicht!
movies2_test_pred %>%
rsq(truth = rating,
estimate = pred)
#> # A tibble: 1 x 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 rsq standard 0.262In dem Fall ist \(R^2\) im Testsample nicht schlechter als im Train-Sample. Häufig ist das anders.
36 Einreichen
data_submit <-
movies2_test_pred %>%
select(ID, pred)write_csv(data_submit,
file = "sauer_sebastian_0123456_prognose.csv")