Hands-on data exploration using R
Sebastian Sauer
![]()
last update: 2018-11-21
You, after this workshop

Well, kinda off...
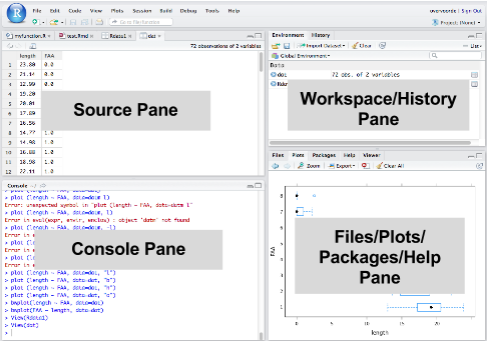
RStudio running
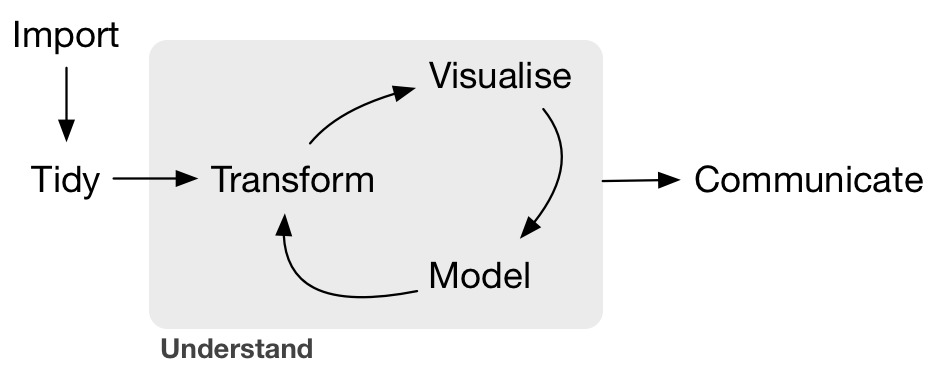
The data analysis (science) pipeline
Get the power of the uni tidyverse

But I love the old way ...

Nice data

Two tidyverse principles
Knock-down principle
Pipe princriple

Filtering rows with filter()
Extract rows that meet logical criteria.
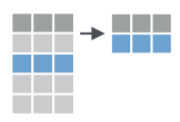
Filter table mtcars such that only rows remain where cols equal 6
filter(mtcars, cyl == 6)#> mpg cyl disp hp drat wt qsec vs am gear carb#> 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4#> 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4#> 3 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1#> 4 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1#> 5 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4#> 6 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4#> 7 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6Select columns with select()
Extract columns by name.
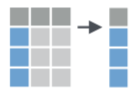
Select the columns cyl and hp. Discard the rest.
select(mtcars, cyl, hp)#> cyl hp#> Mazda RX4 6 110#> Mazda RX4 Wag 6 110#> Datsun 710 4 93#> Hornet 4 Drive 6 110#> Hornet Sportabout 8 175#> Valiant 6 105Add or change a column with mutate
Apply vectorized functions to columns to create new columns.

Define weight in kg for each car.
mtcars <- mutate(mtcars, weight_kg = wt * 2)head(select(mtcars, wt, weight_kg))#> wt weight_kg#> 1 2.620 5.24#> 2 2.875 5.75#> 3 2.320 4.64#> 4 3.215 6.43#> 5 3.440 6.88#> 6 3.460 6.92Summarise a column with summarise()
Apply function to summarise column to single value.

Summarise the values to their mean.
summarise(mtcars, mean_hp = mean(hp))#> mean_hp#> 1 146.6875Group with group_by()
Create "grouped" copy of table. dplyr functions will manipulate each group separately and then combine the results.
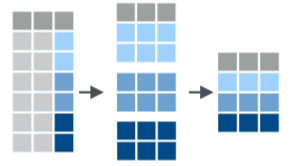
Group cars by am (automatic vs. manual). Then summarise to mean in each group.
mtcars_grouped <- group_by(mtcars, am)summarise(mtcars_grouped, mean_hp = mean(hp))#> # A tibble: 2 x 2#> am mean_hp#> <dbl> <dbl>#> 1 0 160.#> 2 1 127.Why we need diagrams
Anatomy of a diagram
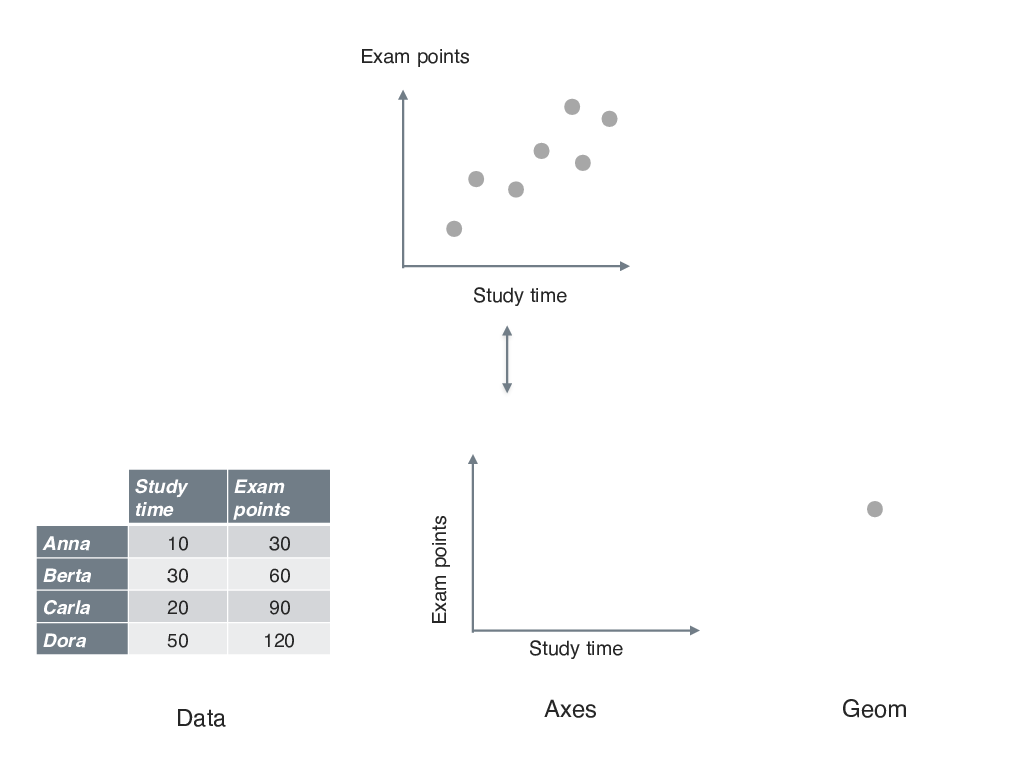
First plot with ggplot
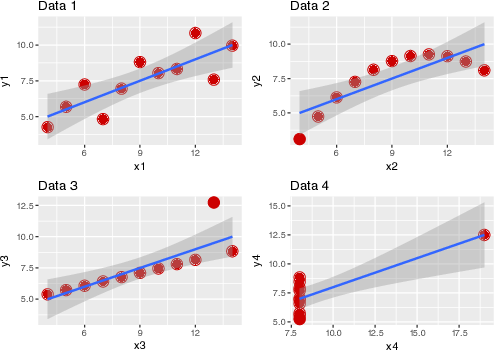
mtcars %>% ggplot() + # initialize plot aes(x = hp, y = mpg) + # define axes etc. geom_point() + # graw points geom_smooth() # draw smoothing line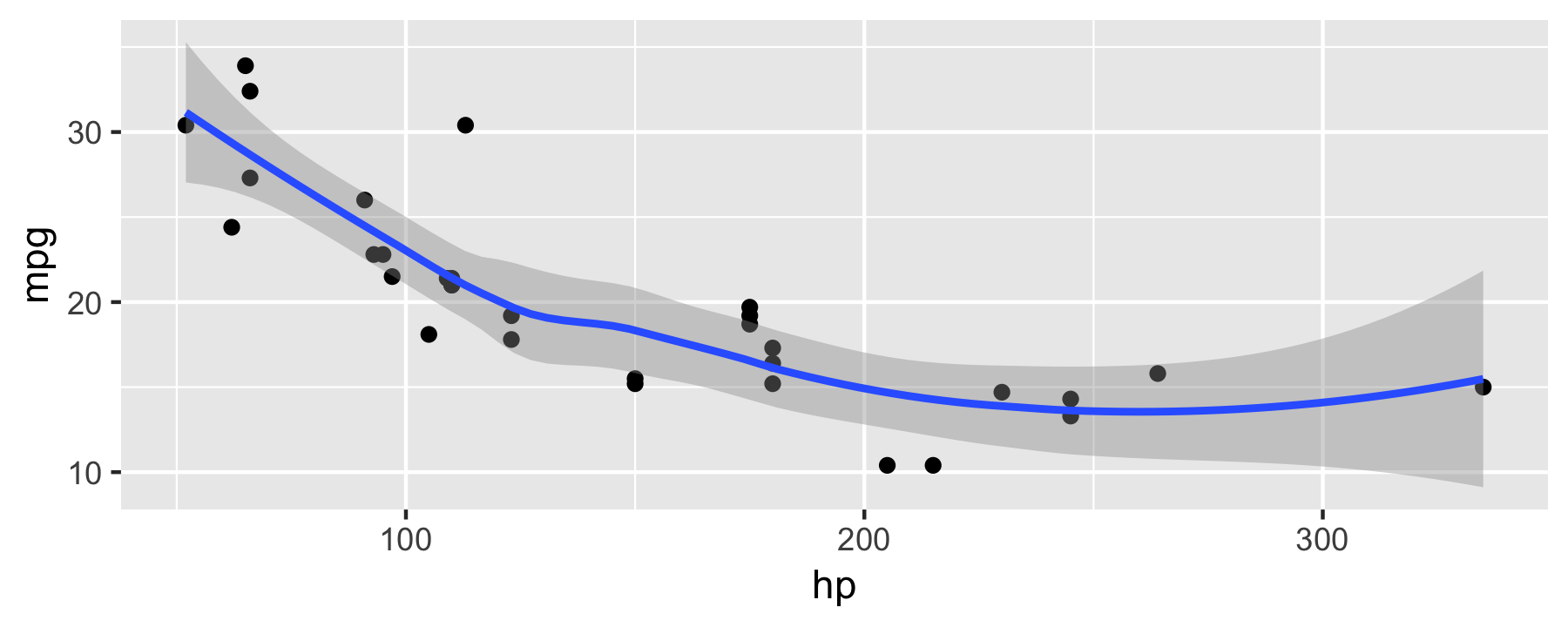
Notice the + in contrast to the pipe %>%.
Groups and colors
mtcars %>% ggplot(aes(x = hp, y = mpg, color = am)) + geom_point() + geom_smooth() + scale_color_viridis_c() + # package "viridis" needed theme_bw()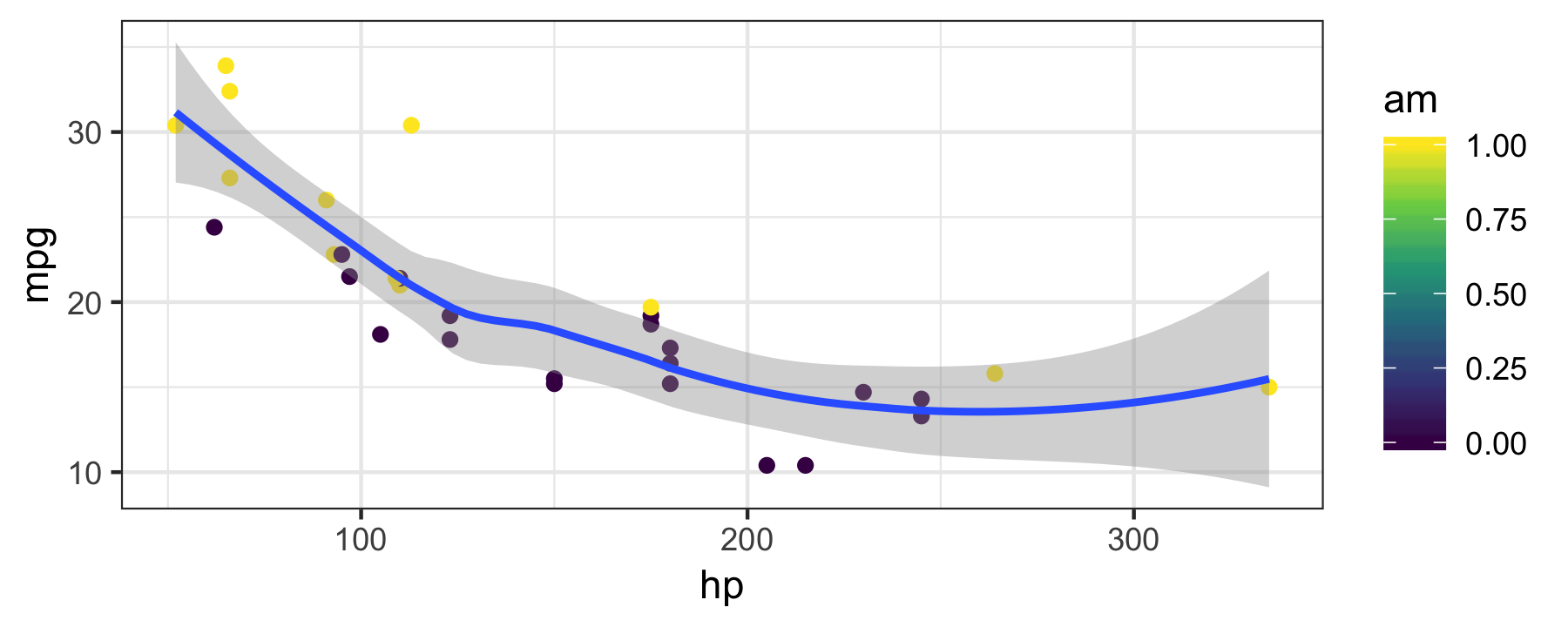
Diagrams - solutions to exercises 1
mtcars_summarized %>% ggplot() + aes(x = cyl, y = mean_hp, color = factor(am), shape = factor(am)) + geom_point(size = 5)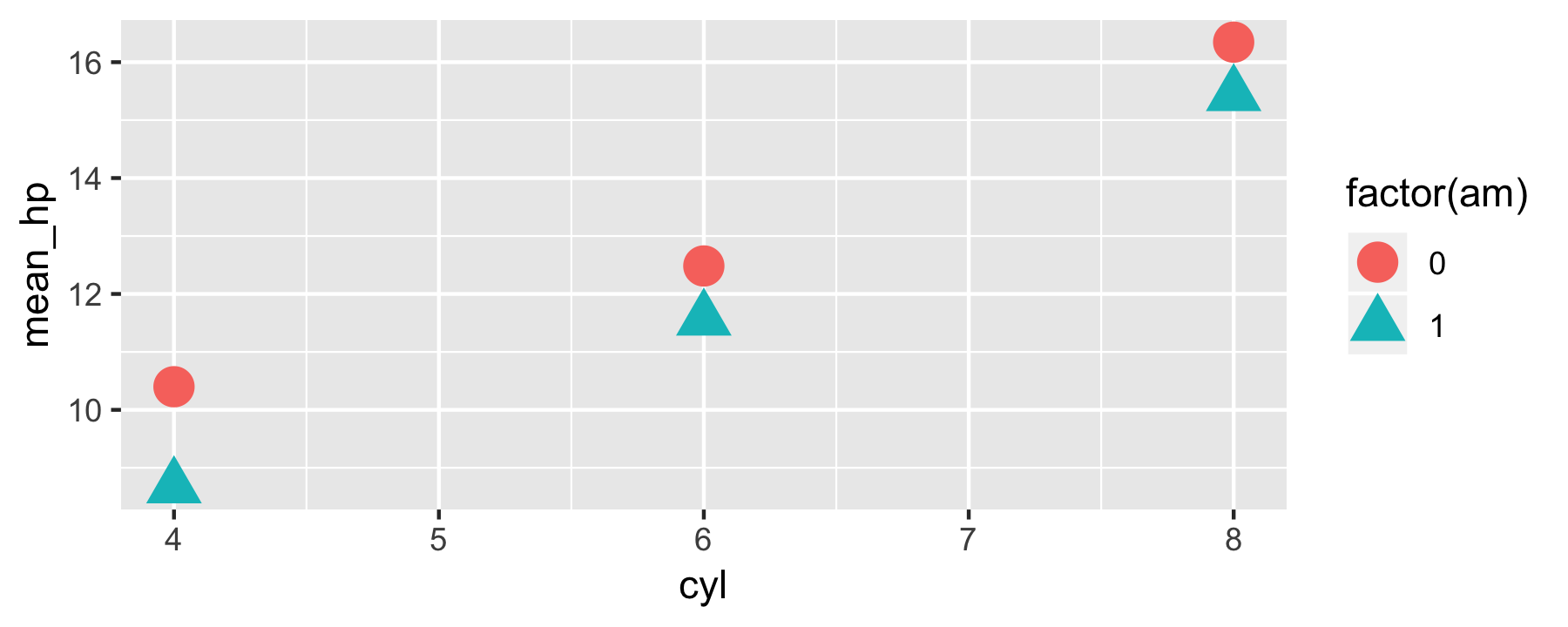
Diagrams - solutions to exercises 2
mtcars_summarized %>% ggplot(aes(x = cyl, color = factor(am), shape = factor(am))) + geom_errorbar(aes(ymin = mean_hp - sd_hp, ymax = mean_hp + sd_hp), width = .2, position = position_dodge(width=0.9)) + geom_point(aes(y = mean_hp), size = 5, position = position_dodge(width=0.9))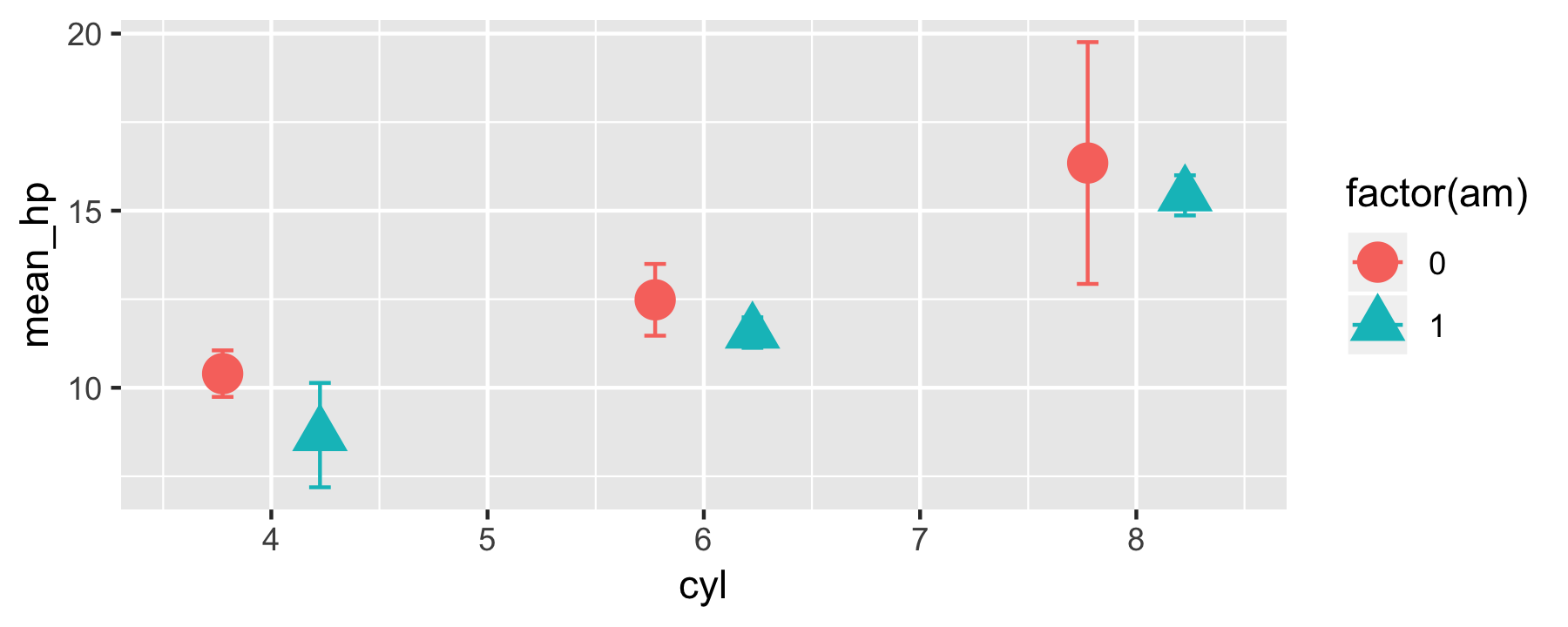
Distribution - quantitative variables
flights %>% ggplot(aes(x = dep_delay)) + geom_histogram() + scale_x_continuous(limits = c(-10, 60))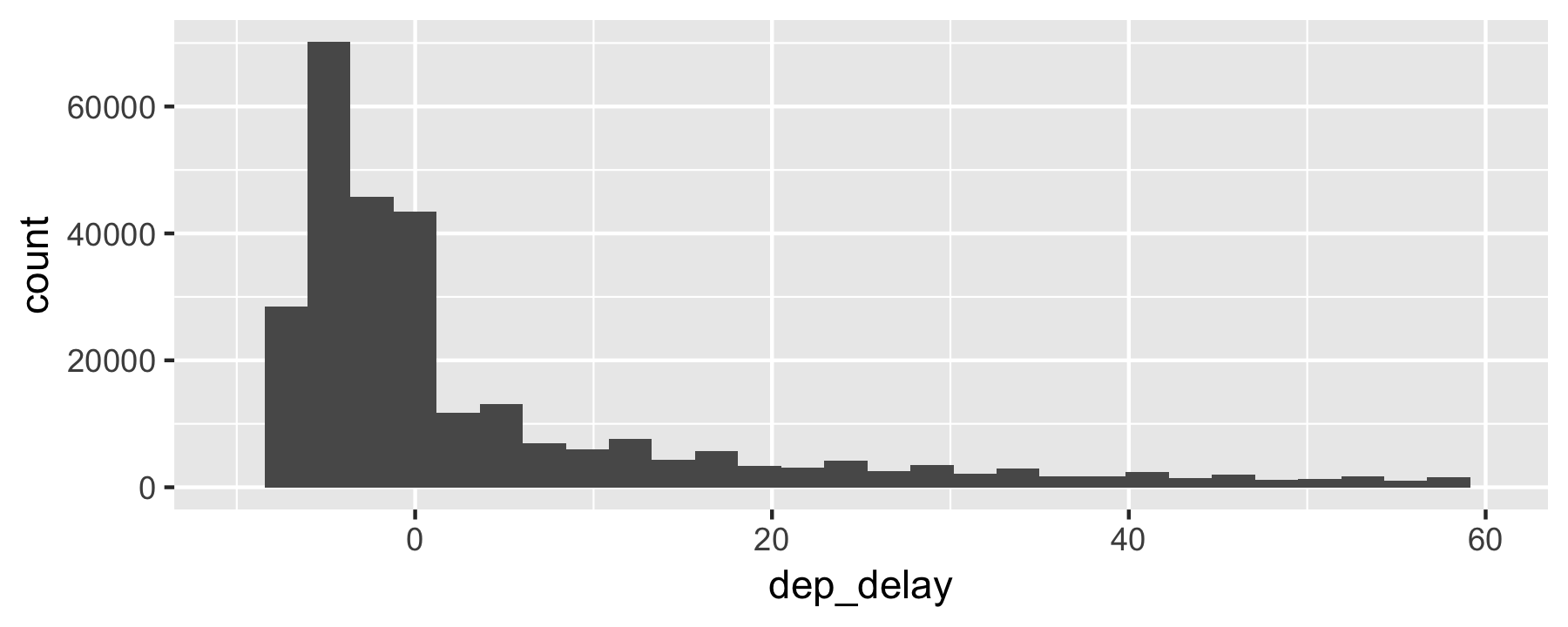
Note the long right tail ("anomaly")
Count missings per row
Advanced.
flights %>% mutate(NA_row = rowSums(is.na(.))) %>% ggplot(aes(x = NA_row)) + geom_histogram()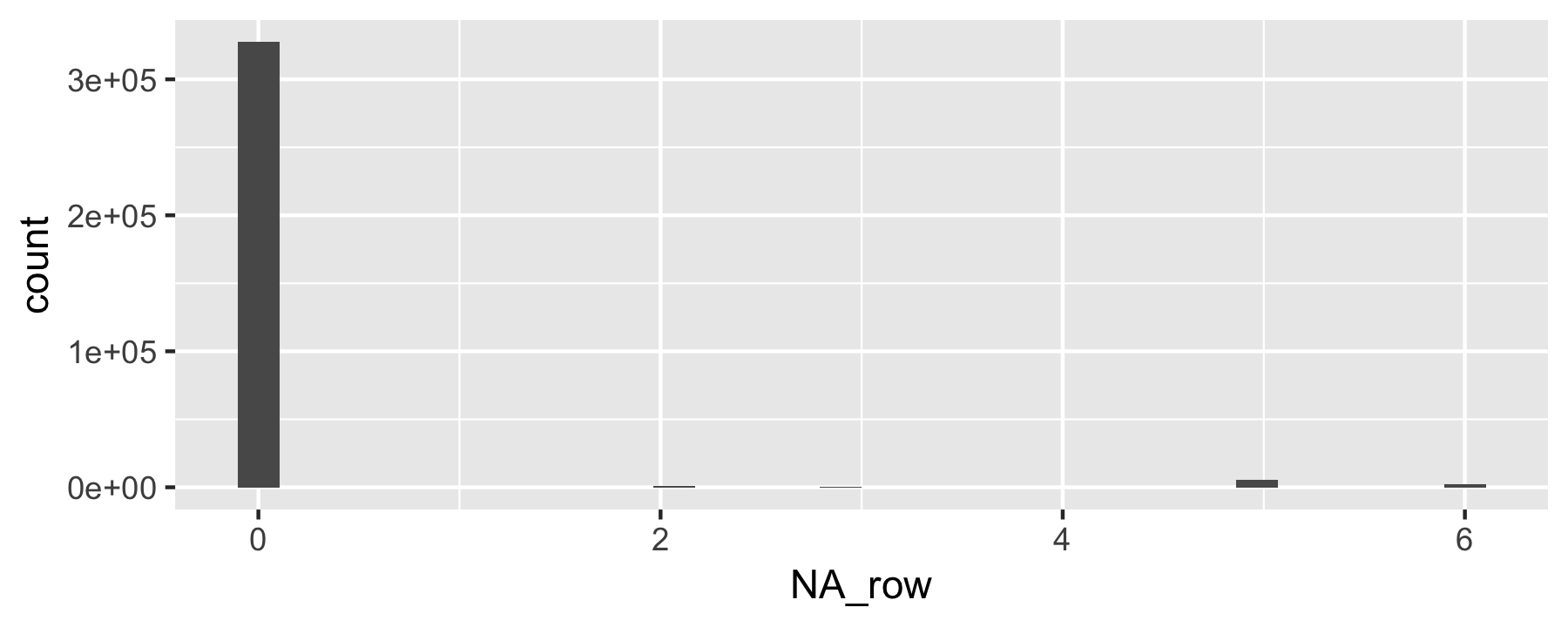
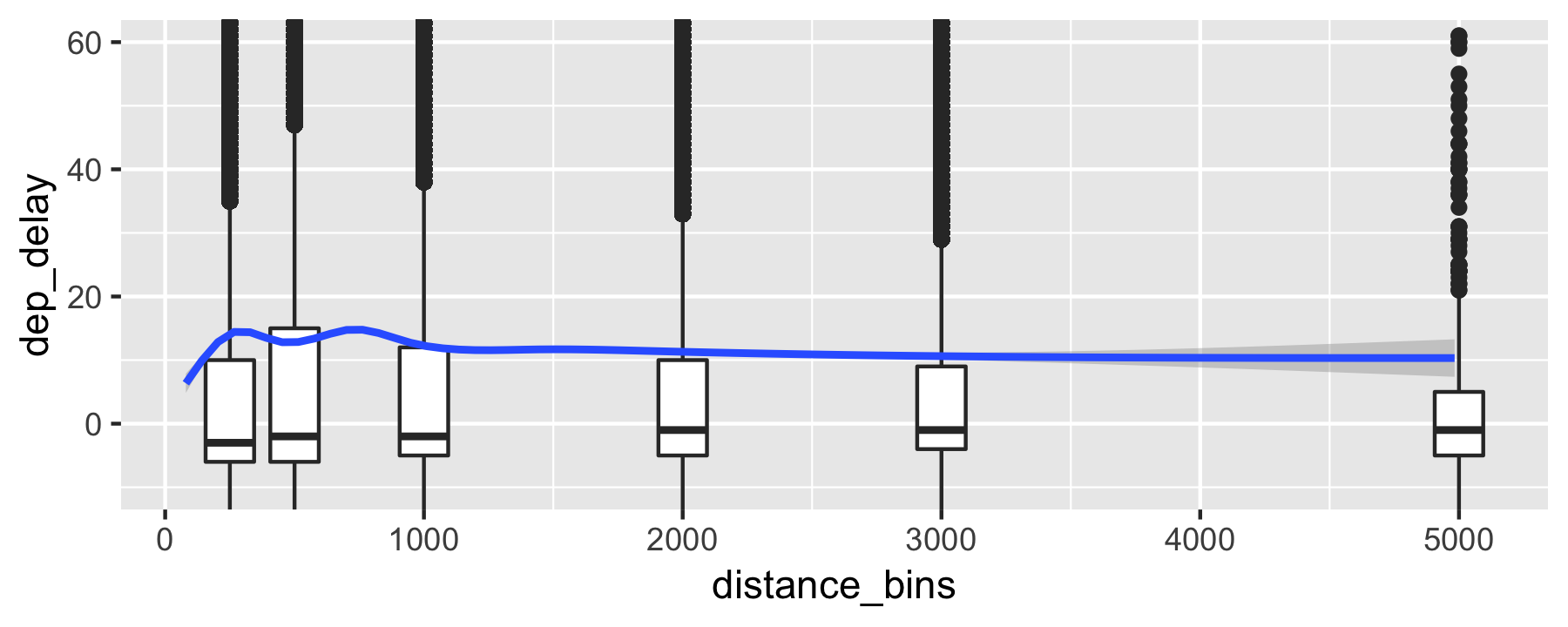
Does distance predicts dep_delay?
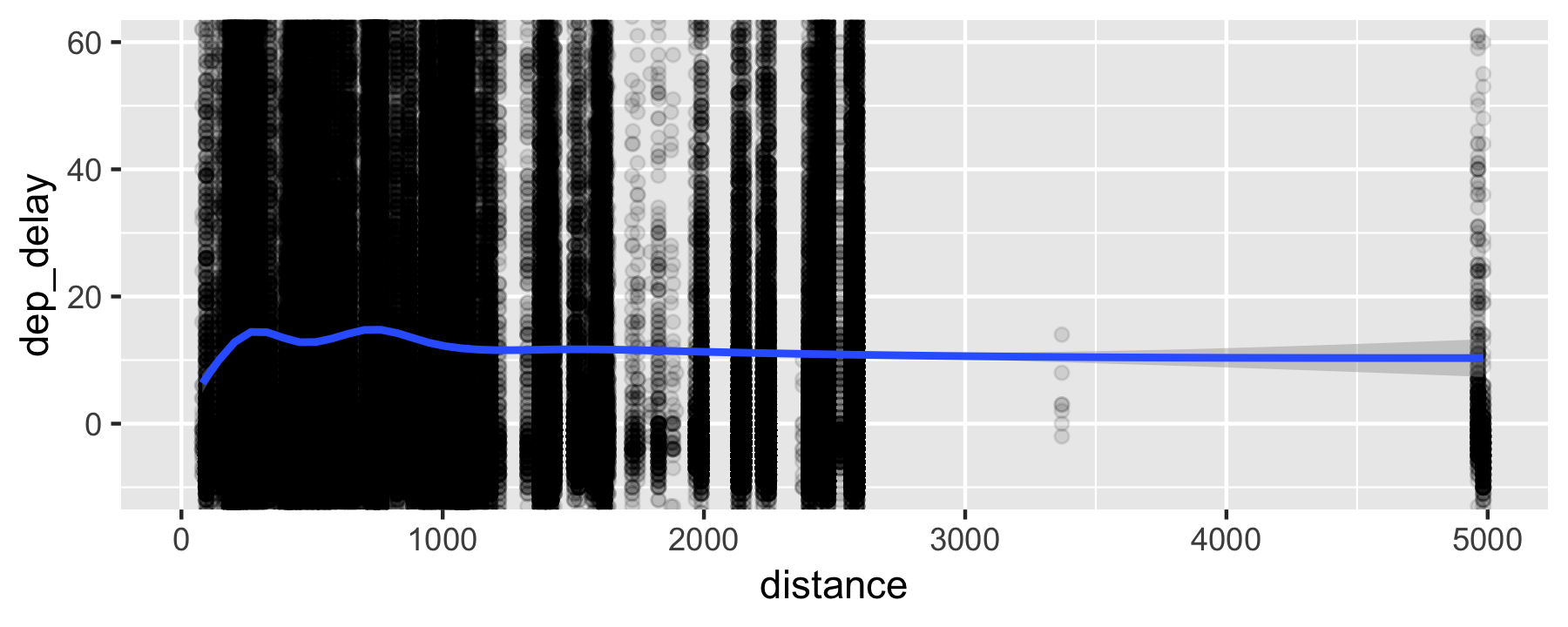
Alternative visualization (binned data)
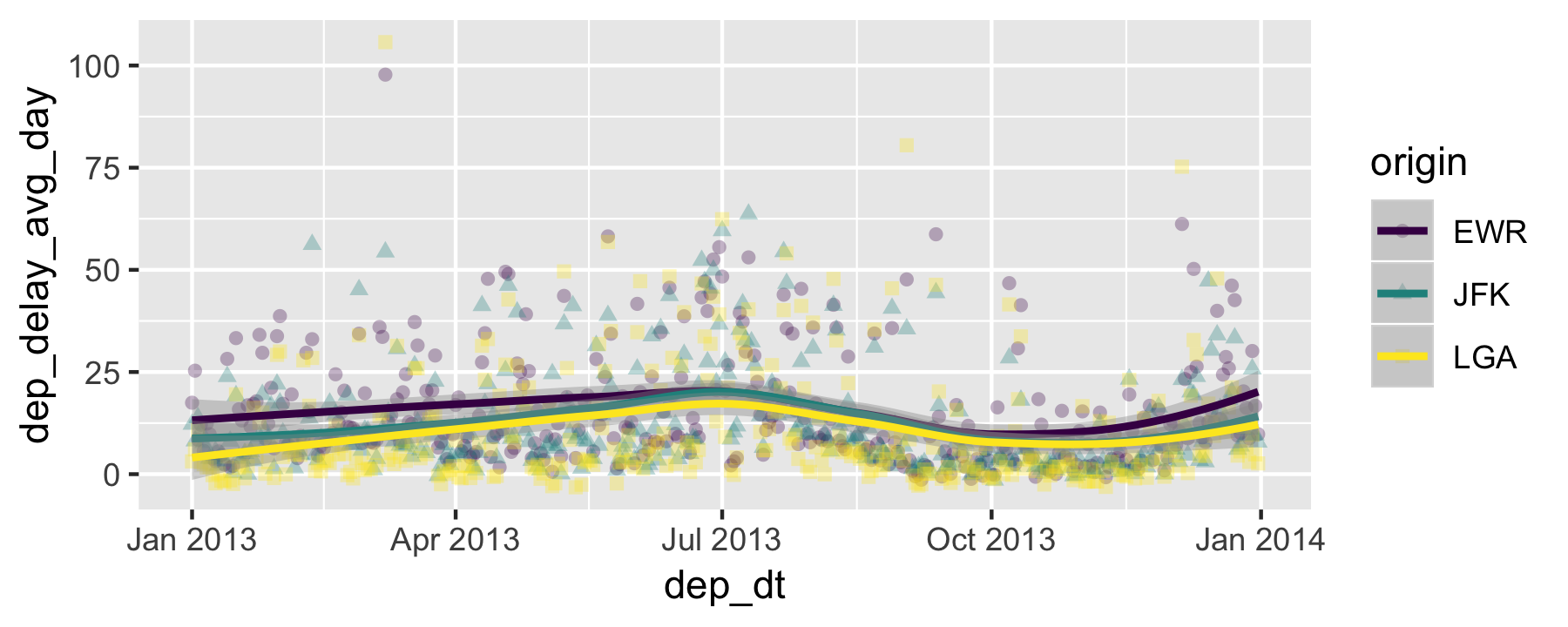
Delay per month (output)
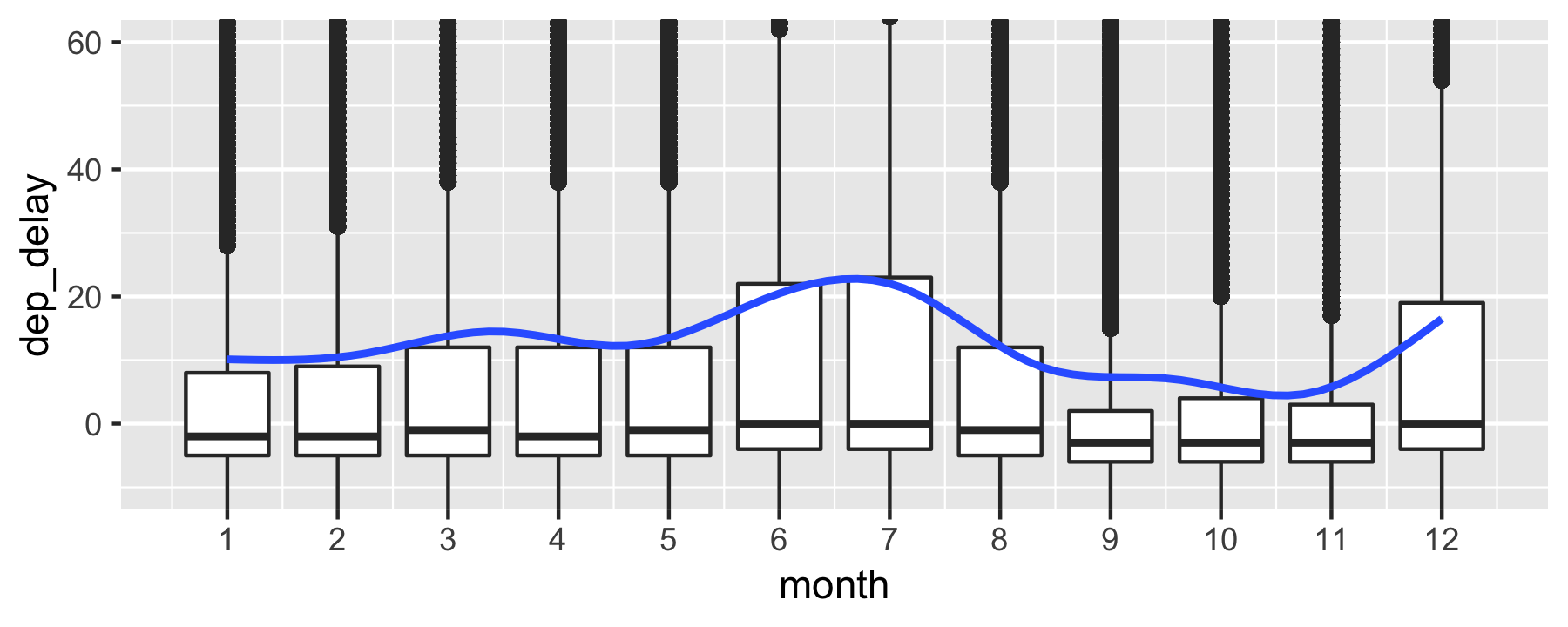
Delay per month - boxplot (output)
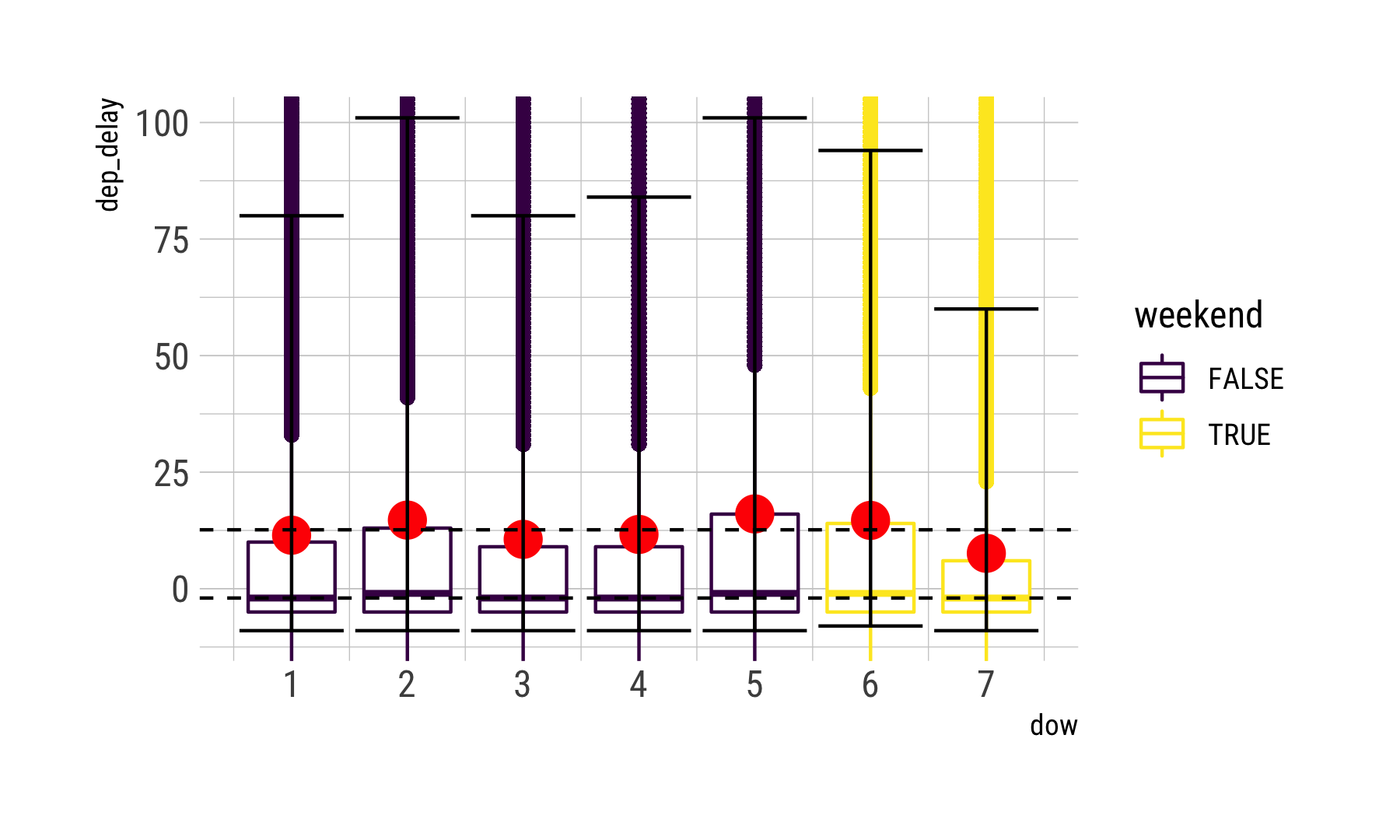
Is it the weekends? (output)
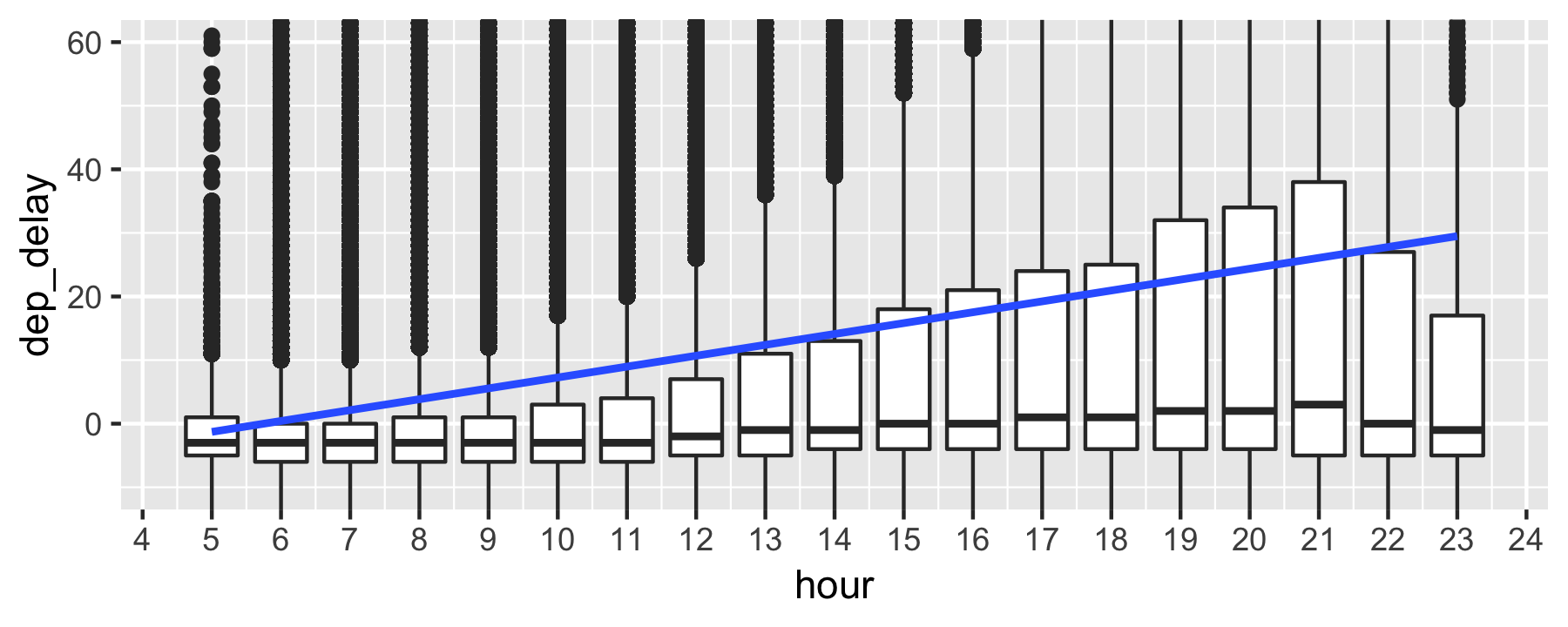
Delay per time of the day (output)
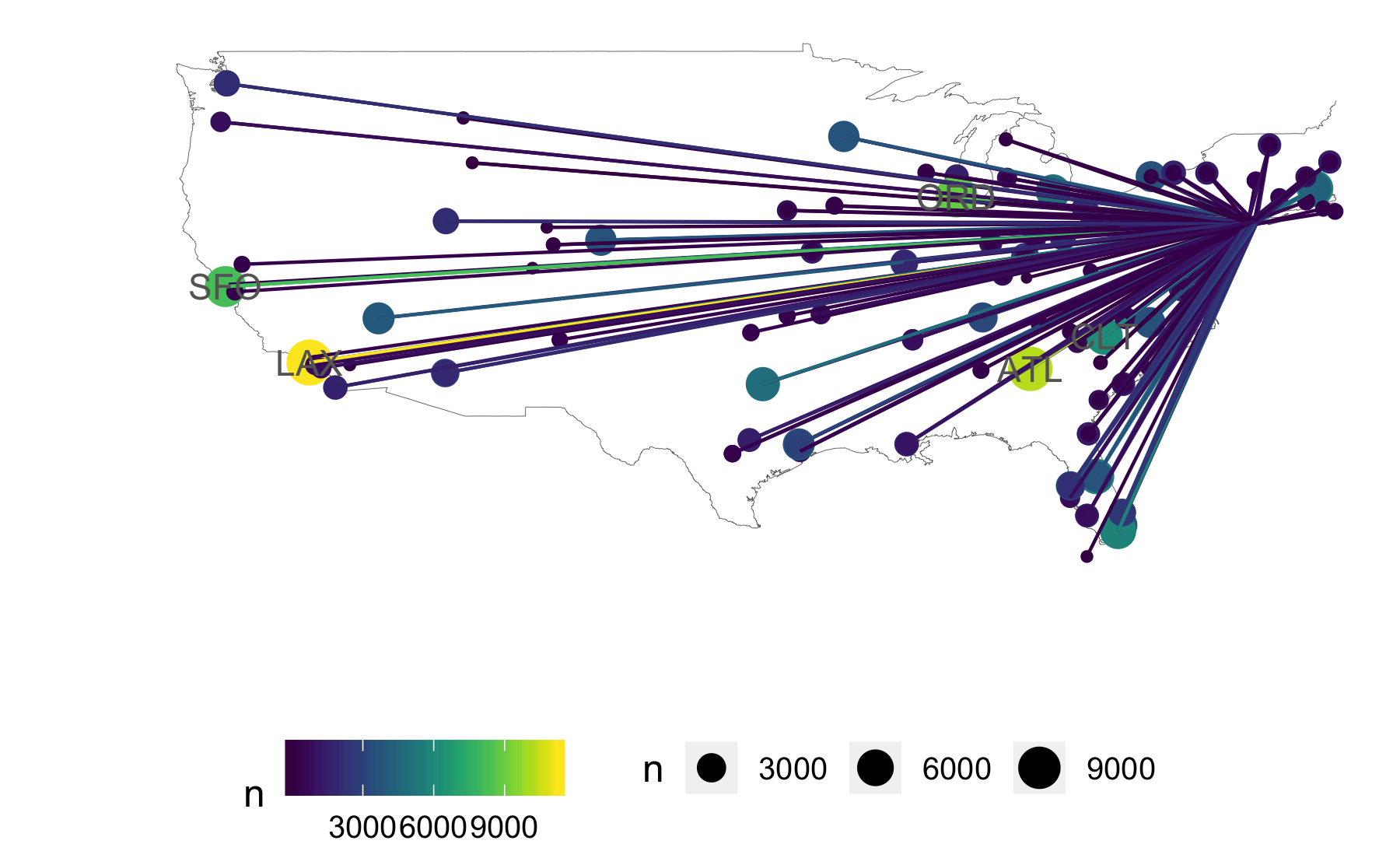
Geo plot flights (output)
Map columns to function with map()
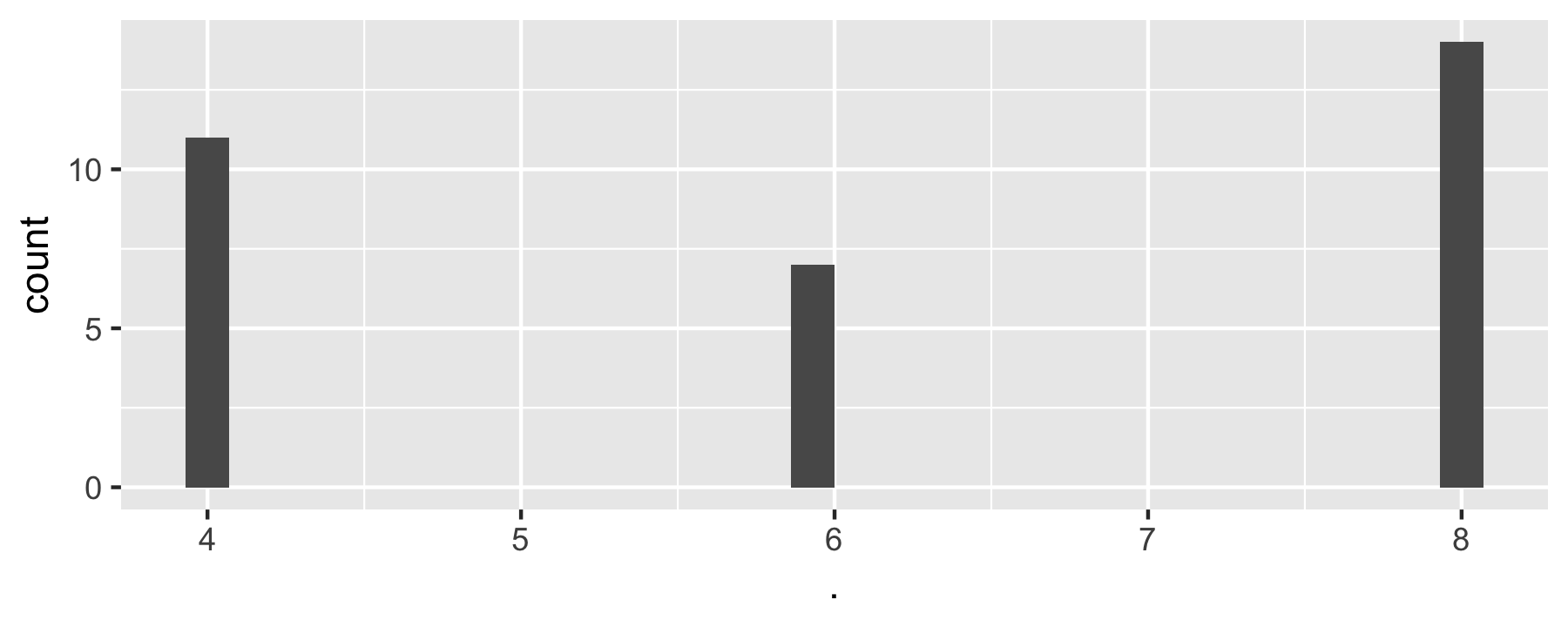
data(mtcars)purrr::map(select(mtcars, 1:2), ~ {ggplot(mtcars, aes(x = .)) + geom_histogram()})#> $mpg#> #> $cyl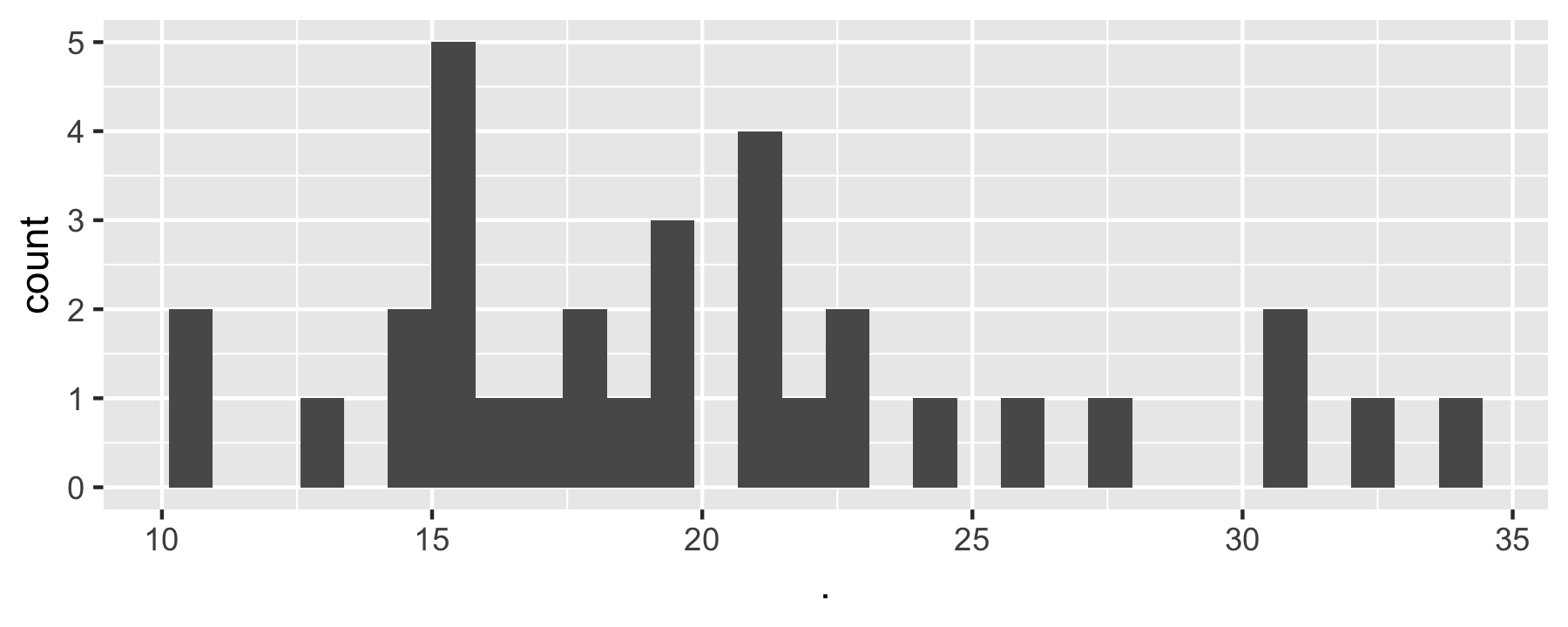
Reshape (transform) dataframe
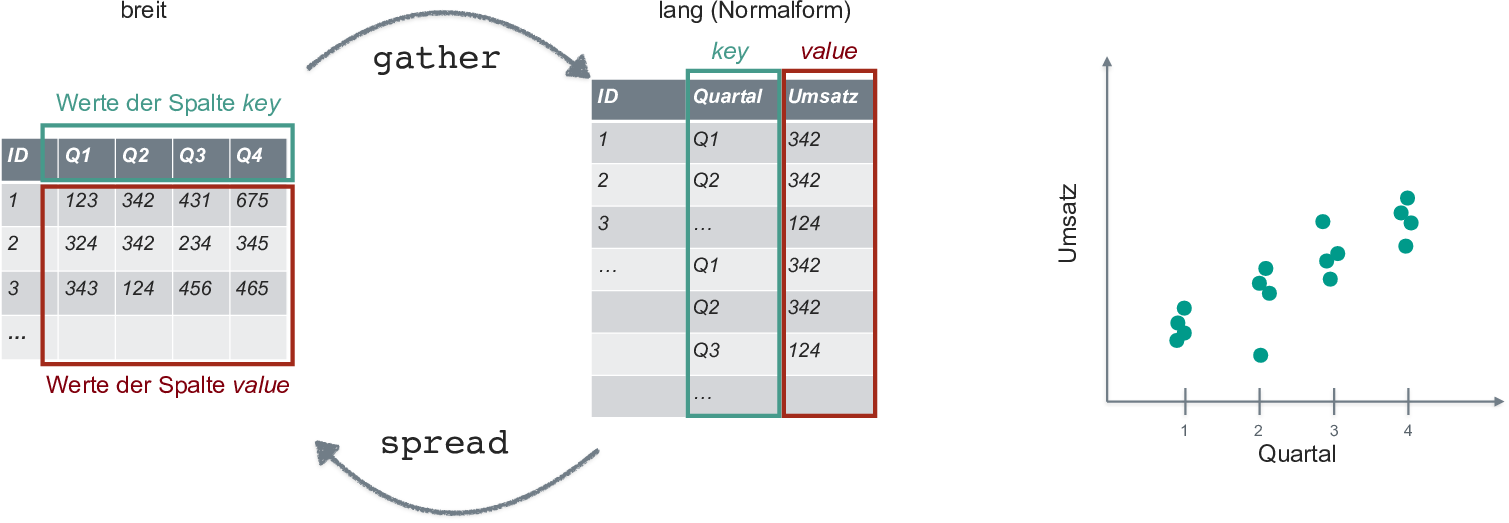
Transform dataframe for plotting
mtcars %>% select_if(is.numeric) %>% gather(key = variable, value = value) %>% ggplot(aes(x = value)) + geom_density() + facet_wrap(~ variable, ncol = 3, scales = "free")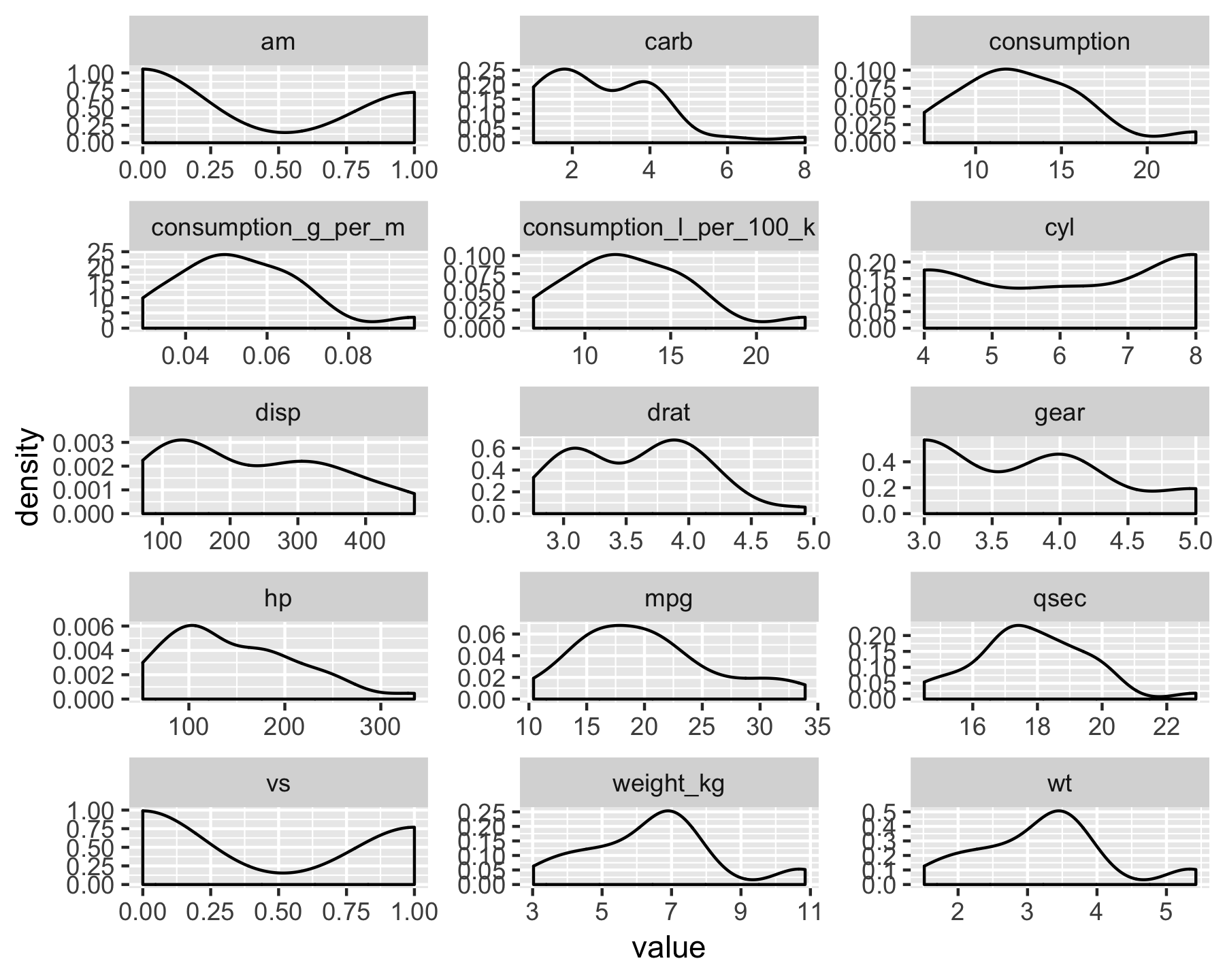
ggplot niceties: Themes
library(hrbrthemes)p2 <- p1 + theme_ipsum() + theme(legend.position = "bottom")p2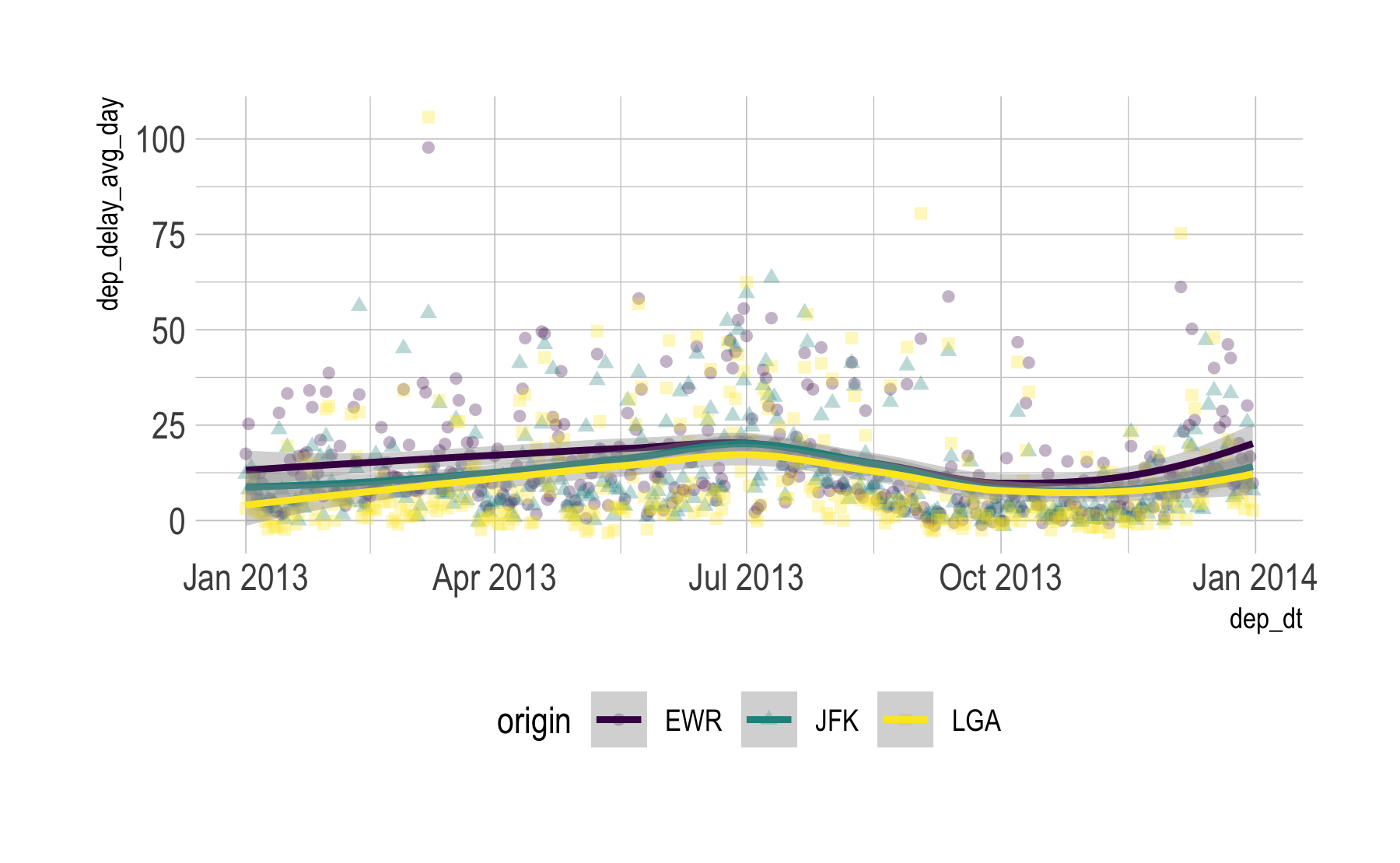
May may need to install fonts upfront; see ?hrbrthemes.
ggplot niceties: Combining plots
library(patchwork)p2 + p2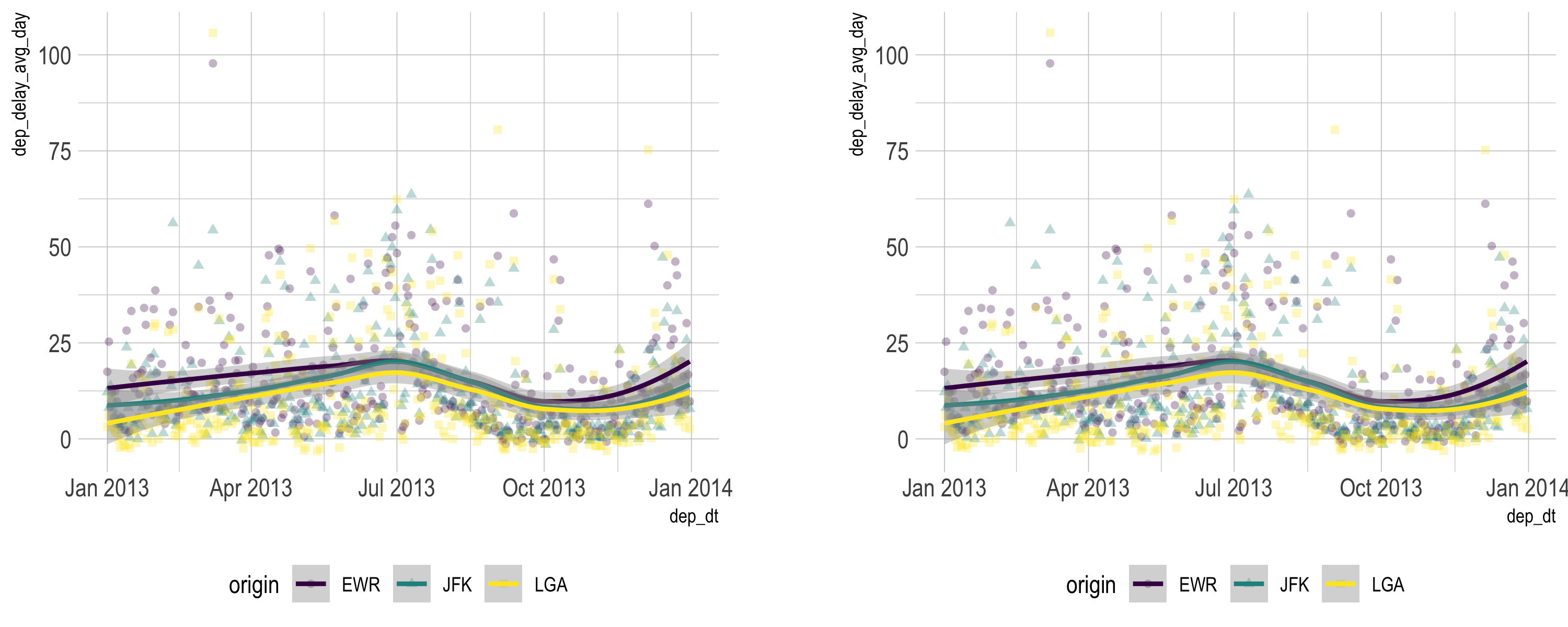





That was quick, but it was a start

{kind=link}
{kind=link}
{kind=link}