The logistic regression is an incredible useful tool, partly because binary outcomes are so frequent in live (“she loves me - she doesn’t love me”). In parts because we can make use of well-known “normal” regression instruments.
But the formula of logistic regression appears opaque to many (beginners or those with not so much math background).
Let’s try to shed some light on the formula by discussing some accessible explanation on how to derive the formula.
Plotting the logistics curve
Let’s have a look at the curve of the logistic regression.
For example, let’s look at the question of whether having extramarital affairs is a function of marital satisfaction.
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.4 ✓ dplyr 1.0.2
## ✓ tidyr 1.1.2 ✓ stringr 1.4.0
## ✓ readr 1.4.0 ✓ forcats 0.5.0## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()data(Affairs, package = "AER")Affairs$has_affairs <- if_else(condition = Affairs$affairs > 0, 1, 0)
Affairs %>%
ggplot() +
aes(x = rating,y = has_affairs) +
geom_jitter() +
geom_smooth(aes(y = has_affairs),
method = "glm", method.args =
list(family = "binomial"),
se = FALSE)## `geom_smooth()` using formula 'y ~ x'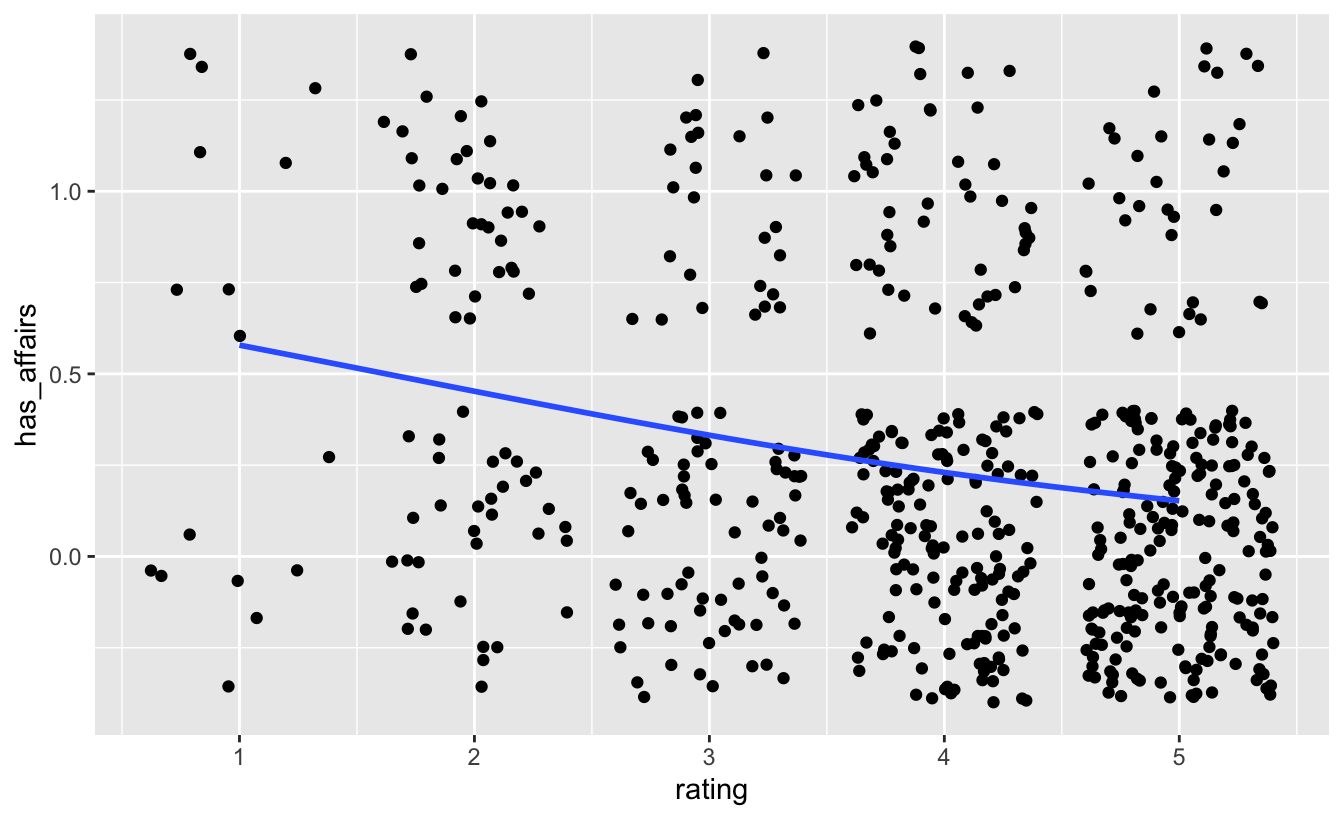
Hm, the curve does not pop out to vividly. Let’s have a look at some other data, why not the Titanic disaster data. Can the survival chance plausible put as a function of the cabin fare?
data(titanic_train, package = "titanic")
titanic_train %>%
ggplot() +
aes(x = Fare,y = Survived) +
geom_point() +
geom_smooth(aes(y = Survived),
method = "glm",
method.args = list(family = "binomial"),
se = FALSE)## `geom_smooth()` using formula 'y ~ x'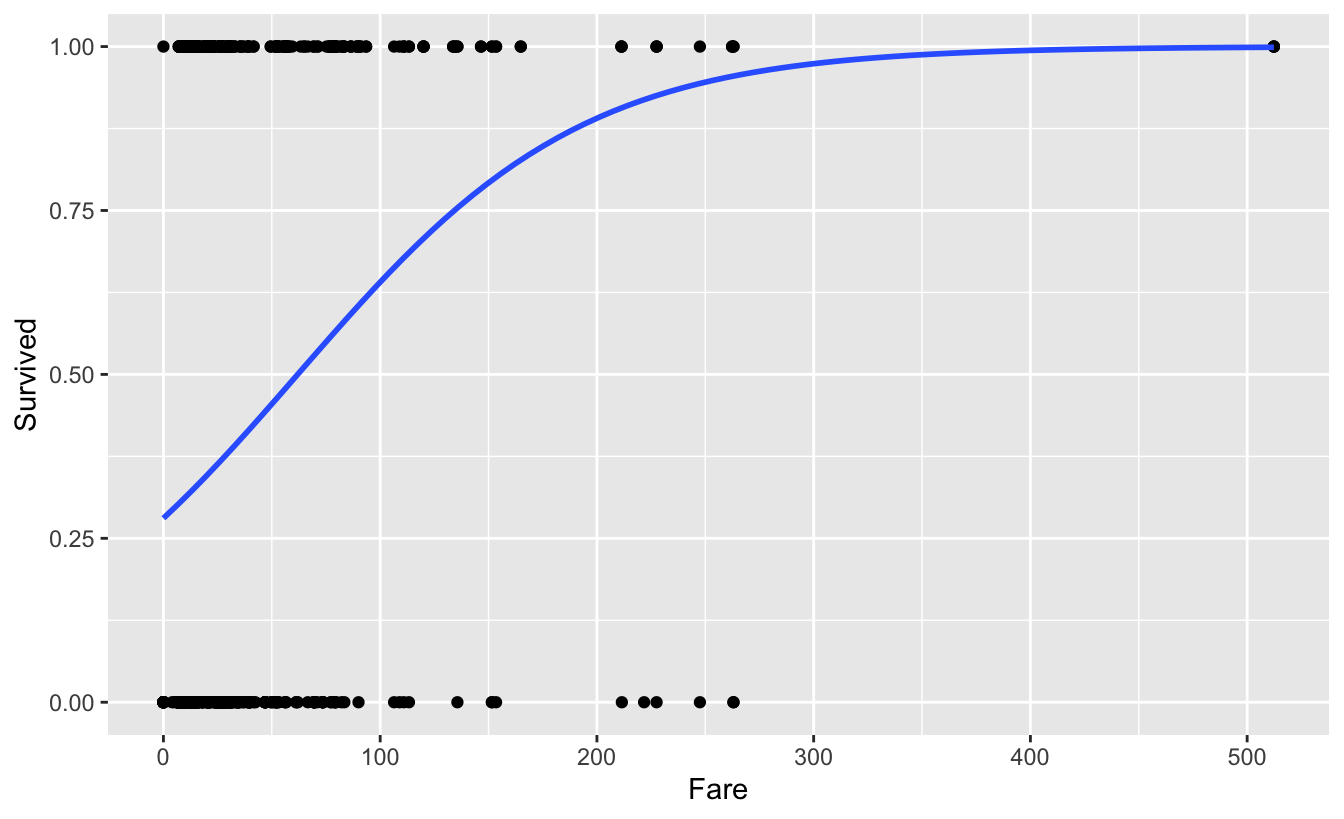
Hm, maybe better to look at the curve in general.
logist <- function(x){
y = exp(x) / (1 + exp(x))
}
p1 <- ggplot(tibble(x = -5:5))
p1 + stat_function(aes(x = x), fun = logist) +
xlab("x")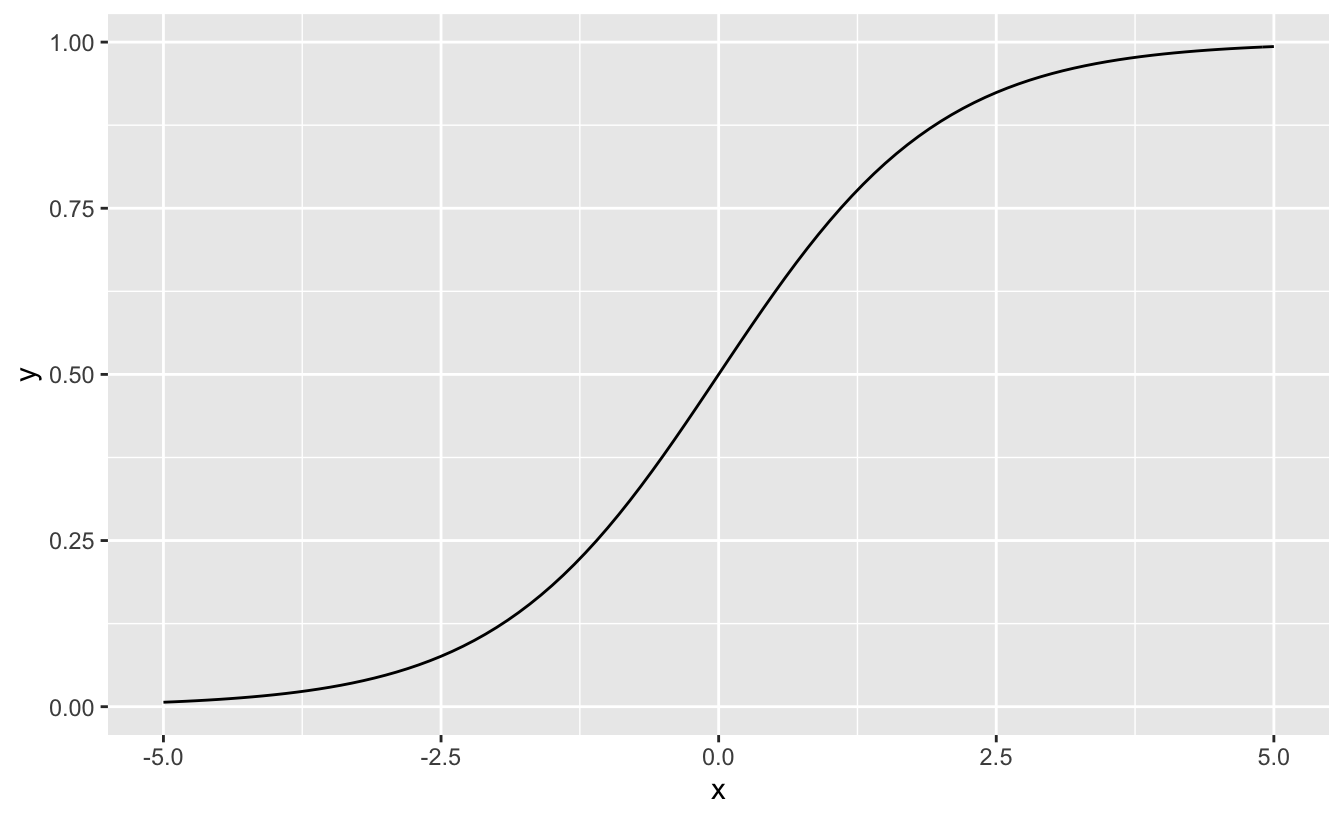
Ok, better.
Functional form
It is well-known that the functional form of the logistic regression curve is
where is Euler’s number (2.718…) and can be any linear combination of predictors such as . indicates that the event in question has occurred (eg., “survived”, “has_affairs”).
Assume that is then
Now what? Well, we would to end up with the “typical” formula of the logistic regression, something like:
where is the Logit, i.e.,
Deriving the formula
Ok, in a first step, let’s take our and divide by the probability of the complementary event. If the probability of event is , the the probability of is . That reflects our modelling of – the probability that event happened – and of , that happened.
Thus:
So wat did we do? We have just replaced by , and have thereby computed the odds.
Next, we multiply the equation by (which is the neutral element, 1), yielding:
In other words, the denominator of the numerator “wandered” down to the denominator.
Now, we can simplify the denominator a bit (common denominator):
Simplifying the denominator further:
But the denominator simplifies to , as can be seen here
so the final solution is .
Ok, great, but what does this solution tells us? It tells us the that the odds simplify to .
Now, let’s take the (natural) logarithm of this expression:
by the rules of exponents algebra.
But .
In sum
The left part of the previous equation is called the logit which is “odds plus logarithm” of , or rather, more precisely, the logarithm of the odds of .
Looking back, what have we gained? We now know that if we take the logit of any linear combination, we will get the logistic regression formula. In simple words: “Take the normal regression equation, apply the logit , and you’ll get out the logistic regression” (provided the criterion is binary).
.
The formula of the logistic regression is similar in the “normal” regression. The only difference is that the logit function has been applied to the “normal” regression formula.
The linearity of the logit helps us to apply our standard regression vocabulary: “If X is increased by 1 unit, the logit of Y changes by b1”. Just insert “the logit”; the rest of the sentence is the normal regression parlance.
Note that the slope of the curve is not linear, hence b1 is not equal for all values of X.