Knime workflow
Consider this Knime workflow:
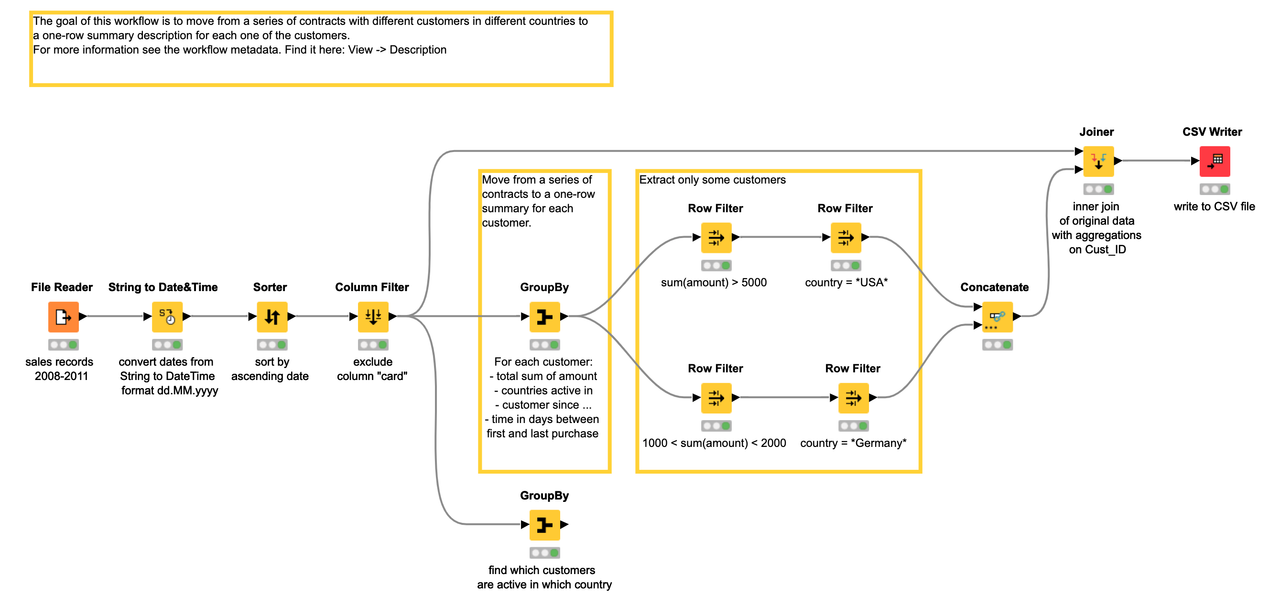
R translation
Setup
library(tidyverse)
library(lubridate)
library(knitr)Chunk 1: Read, sort, filter
datafile <- "https://raw.githubusercontent.com/sebastiansauer/sesa-blog/main/static/datasets/sales_2008-2011.csv"
d <- read_csv(datafile)##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## product = col_character(),
## country = col_character(),
## date = col_date(format = ""),
## quantity = col_double(),
## amount = col_double(),
## card = col_character(),
## Cust_ID = col_character()
## )glimpse(d)## Rows: 47
## Columns: 7
## $ product <chr> "prod_4", "prod_3", "prod_3", "prod_3", "prod_3", "prod_3", …
## $ country <chr> "unknown", "China", "China", "China", "USA", "Brazil", "USA"…
## $ date <date> 2008-12-12, 2009-04-10, 2009-04-10, 2009-05-10, 2009-05-20,…
## $ quantity <dbl> 1, 2, 2, 2, 20, 15, 2, 2, 20, 15, 15, 1, 1, 20, 1, 1, 25, 2,…
## $ amount <dbl> 3, 160, 160, 160, 1600, 1200, 70, 70, 1600, 600, 600, 35, 35…
## $ card <chr> NA, "N", "Y", NA, NA, NA, "Y", NA, NA, NA, "N", "Y", "Y", NA…
## $ Cust_ID <chr> "Cust_8", "Cust_2", "Cust_5", "Cust_2", "Cust_3", "Cust_7", …The data is already recognized as date; no need for transformation.
d %>%
arrange(date) %>%
select(-card) -> dChunk 2: group and aggregate
d %>%
group_by(Cust_ID) %>%
summarise(amount_sum = sum(amount),
country = first(country),
start = min(date),
end = max(date),
duration = end - start) -> d_summarized## `summarise()` ungrouping output (override with `.groups` argument)Chunk 3: filter
d_summarized %>%
filter(amount_sum > 5000) %>%
filter(country == "USA") -> d_summarized_filtered1d_summarized %>%
filter(between(amount_sum,1000, 2000)) %>%
filter(country == "Germany") -> d_summarized_filtered2Chunk 4: concatenate
d_summarized_filtered1 %>%
bind_rows(d_summarized_filtered2) -> d_concatenatedChunk 5: join
Join by ID
d_concatenated %>%
inner_join(d, by = "Cust_ID") -> d_joinedkable(d_joined)| Cust_ID | amount_sum | country.x | start | end | duration | product | country.y | date | quantity | amount |
|---|---|---|---|---|---|---|---|---|---|---|
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_3 | USA | 2009-05-20 | 20 | 1600 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_1 | USA | 2009-07-04 | 2 | 70 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_3 | USA | 2009-08-20 | 20 | 1600 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_3 | USA | 2010-01-03 | 20 | 1600 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_3 | USA | 2010-03-17 | 1 | 80 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_2 | USA | 2010-04-22 | 10 | 400 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_2 | USA | 2010-07-07 | 12 | 480 |
| Cust_3 | 6180 | USA | 2009-05-20 | 2011-01-10 | 600 days | prod_1 | USA | 2011-01-10 | 10 | 350 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_3 | Germany | 2010-01-13 | 1 | 80 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_2 | Germany | 2010-03-31 | 5 | 200 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_2 | Germany | 2011-02-11 | 1 | 40 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_1 | Germany | 2011-03-06 | 10 | 350 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_1 | Germany | 2011-03-18 | 1 | 35 |
| Cust_4 | 1090 | Germany | 2010-01-13 | 2011-03-20 | 431 days | prod_1 | Germany | 2011-03-20 | 11 | 385 |
Chuunk 6: write to csv
write_csv(d_joined, file = "d_joined.csv")