Lernziele:
- Sie kennen zentrale Ziele und Begriffe des Textminings.
- Sie wissen, was ein 'tidy text dataframe' ist.
- Sie können Worthäufigkeiten auszählen.
- Sie können Worthäufigkeiten anhand einer Wordcloud visualisieren.In dieser Übung benötigte R-Pakete:
library(tidyverse) # Datenjudo
library(stringr) # Textverarbeitung
library(tidytext) # Textmining
library(lsa) # Stopwörter
library(SnowballC) # Wörter trunkieren
library(wordcloud) # Wordcloud anzeigenBitte installieren Sie rechtzeitig alle Pakete, z.B. in RStudio über den Reiter Packages > Install.
Ein großer Teil der zur Verfügung stehenden Daten liegt nicht als braves Zahlenmaterial vor, sondern in “unstrukturierter” Form, z.B. in Form von Texten. Im Gegensatz zur Analyse von numerischen Daten ist die Analyse von Texten weniger verbreitet bisher. In Anbetracht der Menge und der Informationsreichhaltigkeit von Text erscheint die Analyse von Text als vielversprechend.
In gewisser Weise ist das Textmining ein alternative zu klassischen qualitativen Verfahren der Sozialforschung. Geht es in der qualitativen Sozialforschung primär um das Verstehen eines Textes, so kann man für das Textmining ähnliche Ziele formulieren. Allerdings: Das Textmining ist wesentlich schwächer und beschränkter in der Tiefe des Verstehens. Der Computer ist einfach noch (?) wesentlich dümmer als ein Mensch, zumindest in dieser Hinsicht. Allerdings ist er auch wesentlich schneller als ein Mensch, was das Lesen betrifft. Daher bietet sich das Textmining für das Lesen großer Textmengen an, in denen eine geringe Informationsdichte vermutet wird. Sozusagen maschinelles Sieben im großen Stil. Da fällt viel durch die Maschen, aber es werden Tonnen von Sand bewegt.
In der Regel wird das Textmining als gemischte Methode verwendet: sowohl qualitative als auch qualitative Aspekte spielen eine Rolle. Damit vermittelt das Textmining auf konstruktive Art und Weise zwischen den manchmal antagonierenden Schulen der qualitativ-idiographischen und der quantitativ-nomothetischen Sichtweise auf die Welt. Man könnte es auch als qualitative Forschung mit moderner Technik bezeichnen - mit den skizzierten Einschränkungen wohlgemerkt.
Zentrale Begriffe
Die computergestützte Analyse von Texten speiste (und speist) sich reichhaltig aus Quellen der Linguistik; entsprechende Fachtermini finden Verwendung:
Ein Corpus bezeichnet die Menge der zu analysierenden Dokumente; das könnten z.B. alle Reden der Bundeskanzlerin Angela Merkel sein oder alle Tweets von “@realDonaldTrump”.
Ein Token (Term) ist ein elementarer Baustein eines Texts, die kleinste Analyseeinheit, häufig ein Wort.
Unter tidy text versteht man einen Dataframe, in dem pro Zeile nur ein Token (z.B. Wort) steht. Synonym könnte man von einem “langen” Dataframe sprechen.
Grundlegende Analyse
Tidy Text Dataframes
Wozu ist es nützlich, einen Text-Dataframe in einen langen Dataframe umzuwandeln? Der Grund ist, dass immer wenn nur ein Wort (allgemeiner: Term) pro Zelle steht, dann können wir die Spalte einfach auszählen. Wir können z.B. count nutzen, um zu zählen, wie häufig ein Wort vorkommt. Sprich: Sobald wir einen langen (Text-)Dataframe haben, können wir unsere bekannte Methoden einsetzen.
Basteln wir uns einen tidy text Dataframe. Wir gehen dabei von einem Vektor mit mehreren Text-Elementen aus, das ist ein realistischer Startpunkt. Unser Text-Vektor1 besteht aus 4 Elementen.
text <- c("Wir haben die Frauen zu Bett gebracht,",
"als die Männer in Frankreich standen.",
"Wir hatten uns das viel schöner gedacht.",
"Wir waren nur Konfirmanden.")Als nächstes machen wir daraus einen Dataframe.
text_df <- data_frame(Zeile = 1:4,
text = text)| Zeile | text |
|---|---|
| 1 | Wir haben die Frauen zu Bett gebracht, |
| 2 | als die Männer in Frankreich standen. |
| 3 | Wir hatten uns das viel schöner gedacht. |
| 4 | Wir waren nur Konfirmanden. |
Übrigens, falls Sie eine beliebige Textdatei einlesen möchten, können Sie das so tun:
text <- read_lines("Brecht.txt")Der Befehl read_lines (aus readr2) liest Zeilen (Zeile für Zeile) aus einer Textdatei.
Wenn Sie keinen Pfad angeben, dann geht R davon aus, dass sich die angegebene Datei im Arbeitsverzeichnis befindet. Welcher Ordner ist Ihr Arbeitsverzeichnis? Klicken Sie in RStudio auf Session > Set Working Directory… um zu erfahren, welcher Ordner im Moment Ihr Arbeitsverzeichnis ist. Dort können Sie auch Ihr Arbeitsverzeichnis einstellen.
Als nächstes “dehnen” wir den Dataframe zu einem tidy text Dataframe (s. Abb. 1); das besorgt die Funktion unnest_tokens aus `tidytext. ‘unnest’ heißt dabei so viel wie ‘Entschachteln’, also von breit auf lang dehnen. Mit ‘tokens’ sind hier einfach die Wörter gemeint (es könnten aber auch andere Analyseeinheiten sein, Sätze zum Beispiel).
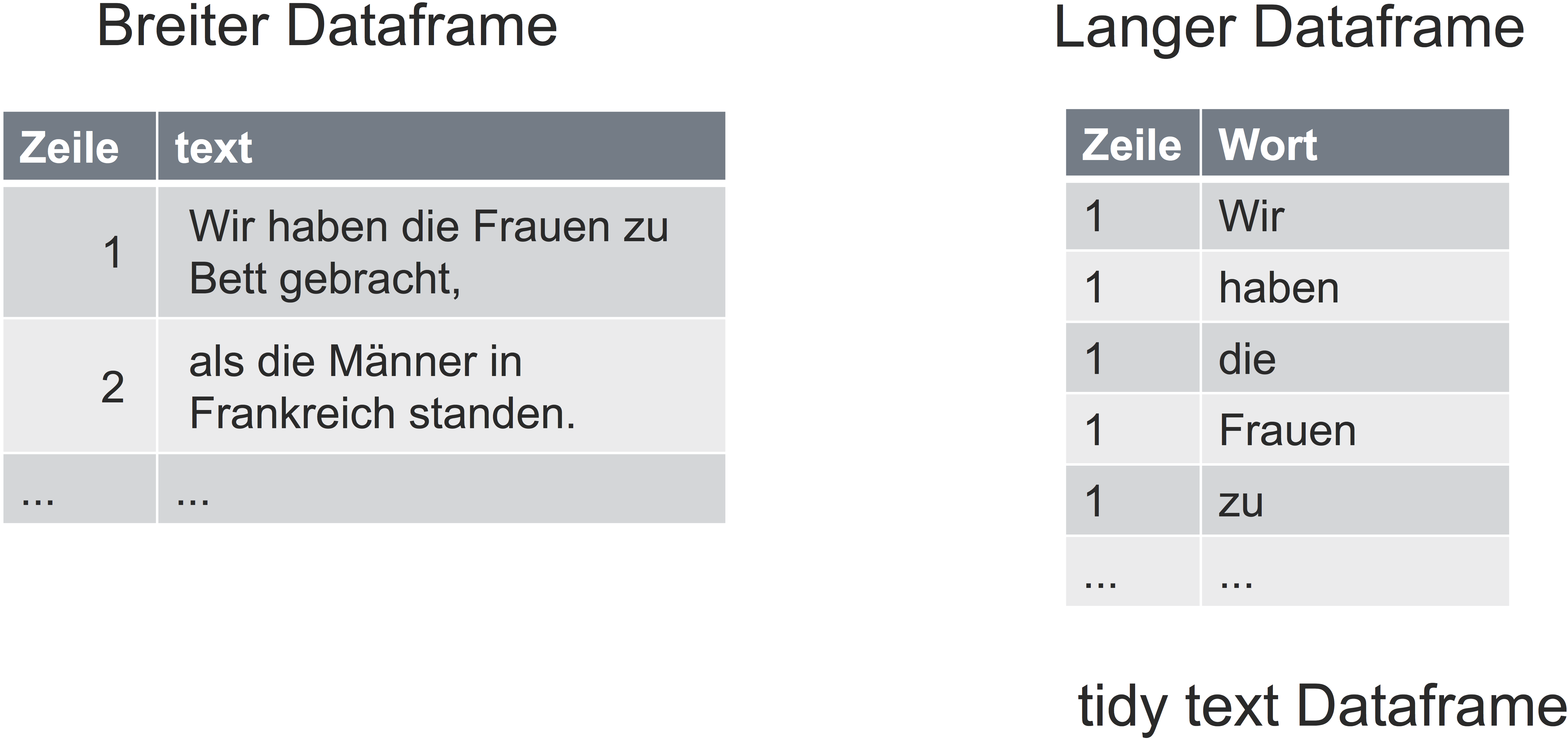
Figure 1: Tidytext
text_df %>%
unnest_tokens(output = wort, input = text) -> tidytext_df
head(tidytext_df)
#> # A tibble: 6 x 2
#> Zeile wort
#> <int> <chr>
#> 1 1 wir
#> 2 1 haben
#> 3 1 die
#> 4 1 frauen
#> 5 1 zu
#> 6 1 bettDer Parameter output sagt, wie neue ‘saubere’ (lange) Spalte heißen soll; input sagt der Funktion, welche Spalte sie als ihr Futter (Input) betrachten soll (welche Spalte in tidy text umgewandelt werden soll).
Nehme den Datensatz "text_df" UND DANN
dehne die einzelnen Elemente der Spalte "text", so dass jedes Element seine eigene Spalte bekommt.
Ach ja: Diese "gedehnte" Spalte soll "wort" heißen (weil nur einzelne Wörter drinnen stehen) UND DANN
speichere den resultierenden Dataframe ab als `tidytext_df`.In einem ‘tidy text Dataframe’ steht in jeder Zeile ein Wort (token) und die Häufigkeit des Worts im Dokument.
Überprüfen Sie, ob das stimmt: Betrachten Sie den Dataframe tidytext_df.
Das unnest_tokens kann übersetzt werden als “entschachtele” oder “dehne” die Tokens - so dass in jeder Zeile nur noch ein Wort (genauer: Token) steht. Die Syntax ist unnest_tokens(Ausgabespalte, Eingabespalte). Nebenbei werden übrigens alle Buchstaben auf Kleinschreibung getrimmt.
Als nächstes filtern wir die Satzzeichen heraus, da die Wörter für die Analyse wichtiger (oder zumindest einfacher) sind.
tidytext_df %>%
filter(str_detect(wort, "[a-z]")) -> tidytext_df_lowercaseIn Pseudo-Code heißt dieser Abschnitt:
Nehme den Datensatz "tidytext_df" UND DANN
filtere die Spalte "wort", so dass nur noch Kleinbuchstaben übrig bleiben (keine Ziffern etc.). FERTIG. Text-Daten einlesen
Als CSV-Datei einlesen
Nun lesen wir Text-Daten ein; das können beliebige Daten sein3. Eine gewisse Reichhaltigkeit im Text ist von Vorteil. Nehmen wir das Parteiprogramm der Partei AfD4. Vor dem Hintergrund des Erstarkens des Populismus weltweit und der großen Gefahr, die davon ausgeht - man blicke auf die Geschichte Europas in der ersten Hälfte des 20. Jahrhunderts - verdienterfordert der politische Prozess und speziell Neuentwicklungen darin unsere besondere Beachtung. Das Parteiprogramm kann hier als CSV-Datei von https://osf.io/b35r7/ eingelesen werden, hier schon als CSV-Datei:
osf_link <- paste0("https://osf.io/b35r7/?action=download")
afd <- read_csv(osf_link)Als PDF oder unstrukturierte Text-Datei einlesen
Häufig sind Textdateien in Textdateien gespeichert, dann kann man mit readr::read_lines Daten, die keine Tabellenstruktur haben einlesen. Ein anderes häufiges Format sind PDF-Dateien; dafür bietet das Paket pdftools die Funktion pdf_text, die den Inhalt einer PDF-Datei einliest. Jede Seite wird dabei als ein Element eines Vektors abgespeichert. Hätten wir die PDF-Datei vorliegen, so könnten wir sie mit pdf_text einlesen. Der resultierende Vektor afd_raw hat 96 Elemente (entsprechend der Seitenzahl des Dokuments). Wandeln wir als nächstes den Vektor in einen Dataframe um. Das AfD-Programm als PDF kann man hier herunterladen: https://osf.io/pngsk/.
afd_pfad <- "data/afd_programm.pdf"
afd_raw <- pdf_text(afd_pfad)
afd <- data_frame(Zeile = 1:96,
afd_raw)Daten sind da - jetzt aufhübschen
Im Ergebnis hätten wir einen Dataframe, ein Prachtstück. Mit head(afd) können Sie sich den Beginn dieses Textvektor anzeigen lassen. Auch die Stopwörter entfernen wir wieder wie gehabt.
afd %>%
unnest_tokens(output = token, input = content) %>%
dplyr::filter(str_detect(token, "[a-z]")) -> afd_longInsgesamt 26396 Wörter5; eine substanzielle Menge von Text. Was wohl die häufigsten Wörter sind?
Worthäufigkeiten auszählen
afd_long %>%
na.omit() %>% # fehlende Werte löschen
count(token, sort = TRUE)
#> # A tibble: 7,087 x 2
#> token n
#> <chr> <int>
#> 1 die 1151
#> 2 und 1147
#> 3 der 870
#> 4 zu 435
#> 5 für 392
#> 6 in 392
#> 7 den 271
#> 8 von 257
#> 9 ist 251
#> 10 das 225
#> # ... with 7,077 more rowsDie häufigsten Wörter sind inhaltsleere Partikel, Präpositionen, Artikel… Solche sogenannten “Stopwörter” sollten wir besser herausfischen, um zu den inhaltlich tragenden Wörtern zu kommen. Praktischerweise gibt es frei verfügbare Listen von Stopwörtern, z.B. im Paket lsa.
data(stopwords_de, package = "lsa")
stopwords_de <- data_frame(word = stopwords_de)
# Für das Joinen werden gleiche Spaltennamen benötigt
stopwords_de <- stopwords_de %>%
rename(token = word)
afd_long %>%
anti_join(stopwords_de) -> afd_no_stopUnser Datensatz hat jetzt viel weniger Zeilen; wir haben also durch anti_join Zeilen gelöscht (herausgefiltert). Das ist die Funktion von anti_join: Die Zeilen, die in beiden Dataframes vorkommen, werden herausgefiltert. Es verbleiben also nicht “Nicht-Stopwörter” in unserem Dataframe. Damit wird es schon interessanter, welche Wörter häufig sind.
afd_no_stop %>%
count(token, sort = TRUE) -> afd_count| token | n |
|---|---|
| deutschland | 190 |
| afd | 171 |
| programm | 80 |
| wollen | 67 |
| bürger | 57 |
| euro | 55 |
| dafür | 53 |
| eu | 53 |
| deutsche | 47 |
| deutschen | 47 |
Ganz interessant; aber es gibt mehrere Varianten des Themas “deutsch”. Es ist wohl sinnvoller, diese auf den gemeinsamen Wortstamm zurückzuführen und diesen nur einmal zu zählen. Dieses Verfahren nennt man “stemming” oder “trunkieren”.
afd_no_stop %>%
mutate(token_stem = wordStem(.$token, language = "de")) %>%
count(token_stem, sort = TRUE) -> afd_count_stemmed
afd_count_stemmed %>%
top_n(10) %>%
knitr::kable(caption = "Die häufigsten Wörter - mit 'stemming'")| token_stem | n |
|---|---|
| deutschland | 219 |
| afd | 171 |
| deutsch | 119 |
| polit | 88 |
| staat | 85 |
| programm | 81 |
| europa | 80 |
| woll | 67 |
| burg | 66 |
| soll | 63 |
Das ist schon informativer. Dem Befehl SnowballC::wordStem füttert man einen Vektor an Wörtern ein und gibt die Sprache an (Default ist Englisch). Denken Sie daran, dass . bei dplyr nur den Datensatz meint, wie er im letzten Schritt definiert war. Mit .$token wählen wir also die Variable token aus afd_raw aus.
Visualisierung
Zum Abschluss noch eine Visualisierung mit einer “Wordcloud” dazu (Abbildung 2).
wordcloud(words = afd_count_stemmed$token_stem,
freq = afd_count_stemmed$n,
max.words = 100,
scale = c(2,.5),
colors=brewer.pal(6, "Dark2"))
Figure 2: Eine Wordwolke zum AfD-Parteiprogramm
Man kann die Anzahl der Wörter, Farben und einige weitere Formatierungen der Wortwolke beeinflussen6.
Weniger verspielt ist eine schlichte visualisierte Häufigkeitsauszählung dieser Art, z.B. mit Balkendiagrammen (gedreht), s. Abbildung 3.
afd_count_stemmed %>%
top_n(30) %>%
ggplot() +
aes(x = reorder(token_stem, n), y = n) +
geom_col() +
labs(title = "mit Trunkierung") +
coord_flip() -> p1
afd_count %>%
top_n(30) %>%
ggplot() +
aes(x = reorder(token, n), y = n) +
geom_col() +
labs(title = "ohne Trunkierung") +
coord_flip() -> p2
Figure 3: Worthäufigkeiten im AfD-Parteiprogramm
Die beiden Diagramme vergleichen die trunkierten Wörter mit den nicht trunkierten Wörtern. Mit reorder ordnen wir die Spalte token nach der Spalte n. coord_flip dreht die Abbildung um 90°, d.h. die Achsen sind vertauscht.
Aufgaben7
Richtig oder Falsch!?
- Unter einem Token versteht man die größte Analyseeinheit in einem Text.
- In einem tidytext Dataframe steht jedes Wort in einer (eigenen) Zeile.
- Eine hinreichende Bedingung für einen tidytext Dataframe ist es, dass in jeder Zeile ein Wort steht (beziehen Sie sich auf den tidytext Dataframe wie in diesem Kapitel erörtert).
- Gibt es ‘Stop-Wörter’ in einem Dataframe, dessen Text analysiert wird, so kommt es - per definitionem - zu einem Stop.
- Mit dem Befehl
unnest_tokenskann man einen tidytext Dataframe erstellen. - Balkendiagramme sind sinnvolle und auch häufige Diagrammtypen, um die häufigsten Wörter (oder auch Tokens) in einem Corpus darzustellen.
- In einem ‘tidy text Dataframe’ steht in jeder Zeile ein Wort (token) aber nicht die Häufigkeit des Worts im Dokument.
- Unter ‘Stemming’ versteht man (bei der Textanalyse), die Etymologie eines Wort (Herkunft) zu erkunden.
Verweise
- Das Buch Tidy Text Minig ist eine hervorragende Quelle vertieftem Wissens zum Textmining mit R.
Nach dem Gedicht “Jahrgang 1899” von Erich Kästner↩
Teil der Tidyverse-Familie↩
Ggf. benötigen Sie Administrator-Rechte, um Dateien auf Ihre Festplatte zu speichern.↩
<geladen am 1. März 2017 von https://www.alternativefuer.de/wp-content/uploads/sites/7/2016/05/2016-06-27_afd-grundsatzprogramm_web-version.pdf>↩
wie kann man sich die Anzahl der Wörter ausgeben lassen? Z.B. so:
count(afd)↩https://cran.r-project.org/web/packages/wordcloud/index.html↩
F, R, F, F, R, R, F, F↩