Analyzing survey results is a frequent endeavor (for some including me). Let’s not think about arguments whether and when surveys are useful or not (for some recent criticism see Briggs' book).
Typically, respondents circle some option ranging from “don’t agree at all” to “completely agree” for each question (or “item”). Typically, four to six boxes are given where one is expected to tick one.
In this tutorial, I will discuss some typical steps to prepare the data for subsequent analyses. The goal is that we have the dataset ready for analyzing with basic preparations (eg. recoding of reversed variables) already done.
Some needed packages.
library(tidyverse)
library(forcats) # recoding
library(psych) # testing for internal consistency
Prepare data
So, first, let’s load some data. That’s a data set of a survey on extraversion. Folks were asked a bunch of questions tapping at their “psychometric extraversion”, and some related behavior, that is, behavior supposed to be related such as “number of Facebook friends”, “how often at a party” etc. Note that college students form the sample.
Data are available only (free as in free and free as in beer).
data_raw <- read.csv("https://sebastiansauer.github.io/data/extra_raw_WS16.csv")
data <- data_raw # backup just in case
Here’s the DOI of this data: 10.17605/OSF.IO/4KGZH.
OK, we got ‘em; a dataset of dimension 501, 24. Let’s glimpse at the data:
glimpse(data)
## Observations: 501
## Variables: 24
## $ Zeitstempel <fctr> ...
## $ Bitte.geben.Sie.Ihren.dreistellen.anonymen.Code.ein..1...Anfangsbuchstabe.des.Vornamens.Ihres.Vaters..2...Anfangsbuchstabe.des.Mädchennamens.Ihrer.Mutter..3..Anfangsbuchstabe.Ihres.Geburstsorts. <fctr> ...
## $ Ich.bin.gerne.mit.anderen.Menschen.zusammen. <int> ...
## $ Ich.bin.ein.Einzelgänger..... <int> ...
## $ Ich.bin.in.vielen.Vereinen.aktiv. <int> ...
## $ Ich.bin.ein.gesprächiger.und.kommunikativer.Mensch. <int> ...
## $ Ich.bin.sehr.kontaktfreudig. <int> ...
## $ Im.Grunde.bin.ich.oft.lieber.für.mich.allein..... <int> ...
## $ Ich.kann.schnell.gute.Stimmung.verbreiten. <int> ...
## $ Ich.gehe.gerne.auf.Partys. <int> ...
## $ Ich.bin.unternehmungslustig. <int> ...
## $ Ich.stehe.gerne.im.Mittelpunkt. <int> ...
## $ Wie.viele.Facebook.Freunde..Kontakte..haben.Sie..wenn.Sie.nicht.bei.Facebook.sind..bitte.LEER.lassen.. <int> ...
## $ Wie.viele..Kater...überreichlicher.Alkoholkonsum..hatten.Sie.in.den.letzten12.Monaten. <fctr> ...
## $ Wie.alt.sind.Sie. <int> ...
## $ Bitte.geben.Sie.Ihr.Geschlecht.an. <fctr> ...
## $ Ich.würde.sagen..ich.bin.extrovertiert. <int> ...
## $ Sie.gehen.alleine.auf.eine.Party..Nach.wie.viel.Minuten.sind.Sie.im.Gespräch. <fctr> ...
## $ Es.wird.ein.Mitarbeiter..m.w..für.eine.Präsentation..Messe..gesucht..Melden.Sie.sich.freiwillig. <fctr> ...
## $ Wie.häufig.waren.Sie.in.den.letzten.12.Monaten.auf.einer.Party. <fctr> ...
## $ Wie.oft.haben.Sie.Kundenkontakt. <fctr> ...
## $ Passt.die.folgende.Beschreibung.auf.Sie...........Eine.extravertierte.Person.ist.jemand..der.seine.Energie.eher.nach.außen.richtet.und.weniger.in.die.innere.Welt.der.Gedanken..Ideen.oder.Vorstellungen..Daher.neigen.extravertierte.Menschen.dazu..in.neuen.Situationen.ohne.zu.zögern.sich.in.die.neue.Situationen.zu.begeben..Zum.Beispiel.würde.eine.extravertierte.Person..die.zum.ersten.Mal.einen.Yogakurs.besucht..sich.nicht.scheuen..direkt.bei.den.Übungen.mitzumachen..Oder.wenn.eine.extravertierte.Person.eine.Kneipe.zum.ersten.besucht..würde.sie.sich.nicht.unbehaglich.fühlen..Man.kann.daher.sagen..dass.extravertierte.Personen.als.aktiv.wahrgenommen.werden.und.sich.zu.Unternehmungen.hingezogen.fühlen..bei.denen.sie.mit.anderen.Personen.in.Kontakt.kommen. <fctr> ...
## $ X <lgl> ...
## $ Wie.sehr.treffen.die.folgenden.Aussagen.auf.Sie.zu..Bitte.denken.Sie.dabei.nicht.an.spezifische.Situationen..sondern.ganz.allgemein..wie.sehr.die.Aussagen.Sie.selbst.in.den.meisten.Bereichen.und.Situationen.in.Ihrem.Leben.beschreiben.Allgemein.wirke.ich.tendenziell.eher.wie.eine.Person..die...... <int> ...
Renaming
Looks like a jungle. Now what? Let’s start with renaming the columns (variables).
extra_colnames <- names(data) # save names in this vector
names(data)[3:12] <- paste("i", formatC(1:10, width = 2, flag = "0"), sep = "")
There’s a saying that naming variables/objects in one of the hardest things in computer stuff. One time I renamed the columns from “i01” to “i26” or so. That’s different to the naming scheme we used now! This ambivalence can lead to confusion (happened to me). That’s why I now follow this rule:
- Renaming strange columns names -> use
v01tov25(or how many columns you have) - Renaming items of e.g. some questionnaire -> use
01toi10etc.
Now columns 3 to 12 are now named “i1”, “i2”, etc. These columns reflect the items of a extraversion questionnaire.
names(data)[1] <- "timestamp"
names(data)[2] <- "code"
names(data)[13] <- "n_facebook_friends"
names(data)[14] <- "n_hangover"
names(data)[15] <- "age"
names(data)[16] <- "sex"
names(data)[17] <- "extra_single_item"
names(data)[18] <- "time_conversation"
names(data)[19] <- "presentation"
names(data)[20] <- "n_party"
names(data)[21] <- "clients"
names(data)[22] <- "extra_vignette"
names(data)[24] <- "extra_description"
data$X <- NULL
Recoding
Importantly, two items are negatively coded; we need to recode them (ie., “yes” gets “no”, and vice versa).
They are:
extra_colnames[c(4, 8)]
## [1] "Ich.bin.ein.Einzelgänger....."
## [2] "Im.Grunde.bin.ich.oft.lieber.für.mich.allein....."
Double check whether still nothing is recoded (I’ve run this code a couple of times already).
identical(data$i02, data_raw[[4]])
## [1] TRUE
identical(data$i06, data_raw[[8]])
## [1] TRUE
OK.
rename(data,
i02r = i02,
i06r = i06) -> data
data %>%
mutate(i02r = recode(i02r, `1` = 4L, `2` = 3L, `3` = 2L, `4` = 1L),
i06r = recode(i06r, `1` = 4L, `2` = 3L, `3` = 2L, `4` = 1L)) -> data
This may lead us too far afield, but let’s see whether the items correlate with each other, and each with the rest. We can compute Cronbach’s Alpha for that purpose
data %>%
select(i01:i10) %>%
psych::alpha() %>%
print
##
## Reliability analysis
## Call: psych::alpha(x = .)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd
## 0.78 0.79 0.81 0.28 3.9 0.015 2.9 0.46
##
## lower alpha upper 95% confidence boundaries
## 0.75 0.78 0.81
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se
## i01 0.75 0.76 0.77 0.26 3.2 0.017
## i02r 0.76 0.77 0.78 0.27 3.4 0.016
## i03 0.81 0.81 0.82 0.33 4.4 0.013
## i04 0.75 0.76 0.77 0.26 3.2 0.017
## i05 0.75 0.76 0.77 0.26 3.2 0.017
## i06r 0.76 0.77 0.78 0.27 3.4 0.016
## i07 0.76 0.77 0.79 0.27 3.4 0.016
## i08 0.76 0.78 0.79 0.28 3.5 0.016
## i09 0.77 0.78 0.79 0.28 3.6 0.016
## i10 0.78 0.79 0.80 0.30 3.8 0.015
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## i01 499 0.69 0.71 0.68 0.60 3.3 0.68
## i02r 498 0.63 0.63 0.59 0.50 3.1 0.80
## i03 500 0.33 0.30 0.16 0.14 1.9 0.92
## i04 498 0.68 0.69 0.67 0.57 3.2 0.73
## i05 498 0.69 0.70 0.68 0.59 3.1 0.77
## i06r 499 0.62 0.62 0.57 0.50 2.9 0.77
## i07 498 0.62 0.62 0.57 0.50 3.0 0.73
## i08 499 0.61 0.60 0.53 0.47 2.9 0.86
## i09 499 0.55 0.57 0.49 0.43 3.4 0.71
## i10 498 0.51 0.49 0.39 0.34 2.2 0.90
##
## Non missing response frequency for each item
## 1 2 3 4 miss
## i01 0.01 0.08 0.46 0.45 0.00
## i02r 0.04 0.16 0.45 0.35 0.01
## i03 0.41 0.33 0.19 0.06 0.00
## i04 0.01 0.16 0.43 0.41 0.01
## i05 0.02 0.20 0.47 0.30 0.01
## i06r 0.05 0.18 0.54 0.22 0.00
## i07 0.02 0.21 0.54 0.23 0.01
## i08 0.06 0.23 0.44 0.27 0.00
## i09 0.01 0.10 0.41 0.47 0.00
## i10 0.21 0.43 0.26 0.10 0.01
Ok, looks good.
I suspect there are rows with no values at, complete blank. Let’s compute the proportion of NAs per row.
rowSums(is.na(data))
## [1] 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 1
## [24] 2 1 2 2 1 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 1 1 1
## [47] 1 1 2 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [70] 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1
## [93] 1 2 1 1 1 2 2 1 1 2 1 1 3 1 1 1 1 2 1 2 1 1 1
## [116] 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0
## [139] 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 2
## [162] 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 1 0 1 0 0 1 1 1
## [185] 1 0 3 0 2 0 0 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 0
## [208] 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 1 1
## [231] 1 1 0 1 1 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
## [254] 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0
## [277] 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
## [300] 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 2 0 0 0 0 0 0
## [323] 1 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0
## [346] 0 0 0 1 0 0 2 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0
## [369] 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 1
## [392] 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
## [415] 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0
## [438] 0 0 0 1 1 0 1 0 0 0 0 0 0 0 0 14 1 1 0 1 0 1 0
## [461] 0 0 0 0 0 11 0 0 0 1 0 0 0 1 1 0 1 1 0 0 0 0 0
## [484] 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 0
table(data$extra_description)
##
## 1 2 3 4 5 6 7 8 10
## 31 118 98 68 44 12 5 1 1
data %>%
mutate(prop_na_per_row = rowSums(is.na(data))/ncol(data)) -> data
count(data, prop_na_per_row)
## # A tibble: 6 × 2
## prop_na_per_row n
## <dbl> <int>
## 1 0.00000000 304
## 2 0.04347826 171
## 3 0.08695652 21
## 4 0.13043478 3
## 5 0.47826087 1
## 6 0.60869565 1
Rowwise means for survey etc.
Let’s compute the mean and the median extraversion.
data %>%
mutate(extra_mean = rowMeans(.[3:12], na.rm = TRUE),
extra_median = apply(.[3:12], 1, median, na.rm = TRUE)) -> data
Cleaning data
The number of hangovers should be numeric, but it isn’t. Let’s see.
count(data, n_hangover) %>% kable
| n_hangover | n |
|---|---|
| 13 | |
| 0 | 98 |
| 1 | 59 |
| 10 | 38 |
| 100 | 1 |
| 106 | 4 |
| 12 | 18 |
| 15 | 10 |
| 153 | 1 |
| 18 | 1 |
| 2 | 63 |
| 20 | 14 |
| 200 | 1 |
| 24 | 8 |
| 25 | 5 |
| 28 | 1 |
| 3 | 42 |
| 30 | 11 |
| 35 | 1 |
| 4 | 25 |
| 40 | 9 |
| 48 | 2 |
| 5 | 38 |
| 50 | 6 |
| 6 | 15 |
| 7 | 2 |
| 70 | 2 |
| 8 | 7 |
| 80 | 1 |
| 9 | 2 |
| 98 | 1 |
| ca. 18-23 | 1 |
| Keinen | 1 |
OK, let’s parse the numbers only; a typical problem in surveys is that respondent do not give numbers where you would like them to give numbers (some survey tools allow you to control what the respondent may put in the field).
data$n_hangover <- parse_number(data$n_hangover)
## Warning: 2 parsing failures.
## row col expected actual
## 132 -- a number
## 425 -- a number .
data$time_conversation <- parse_number(data$time_conversation)
## Warning: 1 parsing failure.
## row col expected actual
## 153 -- a number
data$n_party <- parse_number(data$n_party)
## Warning: 1 parsing failure.
## row col expected actual
## 270 -- a number
# data$n_clients <- parse_number(data$clients)
For the item “how many clients do you see each weak”, things are more difficult, see:
data %>%
count(clients)
## # A tibble: 19 × 2
## clients n
## <fctr> <int>
## 1 51
## 2 0 3
## 3 100 1
## 4 3 Mal pro Woche 1
## 5 gar nicht 1
## 6 habe keine Kunden 1
## 7 ich arbeite ncht 1
## 8 Ich habe keinen Kundenkontakt 1
## 9 im Schnitt 1 Mal pro Monat 30
## 10 im Schnitt 1 Mal pro Quartal (oder weniger) 51
## 11 im Schnitt 1 Mal pro Tag 50
## 12 im Schnitt 1 Mal pro Woche 78
## 13 im Schnitt mehrfach pro Tag 225
## 14 keinen 1
## 15 nie 2
## 16 Nie 1
## 17 Nö 1
## 18 täglich zwischen 20-50 1
## 19 Telfonisch täglich, Face to Face 1xWoche 1
There are some values/words indicating that the respondent does not see any clients at all. Let’s recode them to “I am not having personal contact to clients” (or, shorter no).
data %>%
mutate(client_freq = recode(clients, "gar nicht" = "0",
"habe keine Kunden" = "0",
"keinen" = "0",
"Nie" = "0",
"Nö" = "0",
"Ich habe keinen Kundenkontakt" = "0",
"ich arbeite ncht " = "0",
"nie" = "0",
" " = "0")) -> data
data %>%
count(client_freq)
## # A tibble: 11 × 2
## client_freq n
## <fctr> <int>
## 1 51
## 2 0 12
## 3 100 1
## 4 3 Mal pro Woche 1
## 5 im Schnitt 1 Mal pro Monat 30
## 6 im Schnitt 1 Mal pro Quartal (oder weniger) 51
## 7 im Schnitt 1 Mal pro Tag 50
## 8 im Schnitt 1 Mal pro Woche 78
## 9 im Schnitt mehrfach pro Tag 225
## 10 täglich zwischen 20-50 1
## 11 Telfonisch täglich, Face to Face 1xWoche 1
Ok, looks good, but still a bit work left.
data %>%
mutate(client_freq = recode(client_freq, "100" = "3",
"im Schnitt 1 Mal pro Quartal (oder weniger)" = "1",
"im Schnitt 1 Mal pro Monat" = "2",
"im Schnitt 1 Mal pro Woche" = "3",
"im Schnitt 1 Mal pro Tag" = "4",
"im Schnitt mehrfach pro Tag" = "5",
"täglich zwischen 20-50" = "5",
"Telfonisch täglich, Face to Face 1xWoche" = "5",
"3 Mal pro Woche" = "4")) -> data
data$client_freq <- factor(data$client_freq) # drops unused levels
data %>%
count(client_freq)
## # A tibble: 7 × 2
## client_freq n
## <fctr> <int>
## 1 51
## 2 0 12
## 3 3 79
## 4 4 51
## 5 2 30
## 6 1 51
## 7 5 227
Finally, let’s reorder the values from 0 to 5.
data$client_freq[data$client_freq == ""] <- NA
data %>%
mutate(client_freq = factor(client_freq, levels = c("0", "1", "2", "3", "4", "5", NA))) -> data
Pooh, what a mess. Better force respondent to select from a given set of answers, than we do not have that hassle.
Checking NA’s for items
data %>%
select(i01:i10) %>%
gather %>%
filter(is.na(value)) %>%
count
## # A tibble: 1 × 1
## n
## <int>
## 1 24
Hm, let’s see in more detail.
data %>%
select(i01:i10) %>%
filter(!complete.cases(.))
## i01 i02r i03 i04 i05 i06r i07 i08 i09 i10
## 1 4 4 3 NA 4 3 3 3 3 2
## 2 4 3 3 3 2 4 NA 4 4 3
## 3 3 3 1 2 3 3 2 1 3 NA
## 4 3 3 1 NA 3 2 3 2 3 1
## 5 4 1 1 4 NA 1 4 3 3 2
## 6 3 NA 2 3 2 4 2 2 4 2
## 7 NA NA NA NA NA NA NA NA NA NA
## 8 NA NA 2 2 NA NA NA NA NA NA
Hm, not so many cases have NAs. Let’s just exclude them, that’s the easiest, and we will not lose much (many cases, that is).
data %>%
select(i01:i10) %>%
filter(complete.cases(.)) %>% nrow
## [1] 493
data %>%
select(i01:i10) %>%
na.omit -> data_items
So, we are more or less done now. Last thing we do, is to have a look at the distribution of data_items whether it looks plausible, as some kind of coarse sense check.
data_items %>%
select(i01:i10) %>%
gather %>%
ggplot +
aes(x = value) +
geom_bar()+
facet_wrap(~key, ncol = 4)
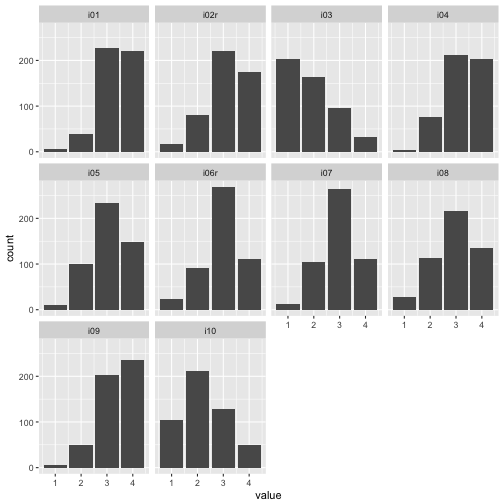
Appears ok!
Ok, let’s save the data file as the last step (here, we simple chose the working directory)
write.csv(data, file = "extra.csv")